
How To Avoid Common Difficulties In Your Data Science Programming Environment

Reduce the incidental issues in your programming environment so you can focus on the important data science problems.
Consider the following situation: you’re trying to practice your soccer skills, but each time you take to the field, you encounter some problems: your shoes are on the wrong feet, the laces aren’t tied correctly, your socks are too short, your shorts are too long, and the ball is the wrong size. This is a ridiculous situation, but it’s analogous to that many data scientists find themselves in due to a few common, easily solvable issues:
- Failure to manage library dependencies
- Inconsistent code style
- Inconsistent naming conventions
- Different development environments across a team
- Not using an integrated development environment for code editing
All of these mistakes “trip” you up, costing you time and valuable mental resources worrying about small details. Instead of solving data science problems, you find yourself struggling with incidental difficulties trying to set up your environment or get your code to run. Fortunately, the above issues are simple to fix with the right tooling and approach. In this article, we’ll look at best practices for a data science programming environment that will give you more time and concentration for working on the problems that matter.
1. Failing to Manage Libraries (Dependencies)
Nothing is more frustrating than writing code that works perfectly one day and then discovering it has numerous errors the next without you changing a character. Almost every time I encounter this problem, it has a single cause: failing to keep track of which version of libraries you are using in your code. This problem is so common and so frustrating that its name is dependency hell.
To get over this, you have to remember libraries have versions: when you say you use pandas, that’s incorrect; you actually use pandas==0.24.0 or pandas==0.19.2 , etc. Every library you import in a project will be at a specific version and recording the version for your project is crucial to avoid terrible moments of broken code. There are many options for fixing this revolving around the idea of creating an isolated environment: a managed installation of Python with its own packages separate from your system Python.
- Python’s built-in
[venv](https://docs.python.org/3/library/venv.html?): this comes with Python but is a little hard to use. [conda](https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html?)virtual environments: use the conda package manager to create and maintain virtual environments. This is the approach I’d recommend for those new to virtual environments.[pipenv](https://docs.pipenv.org/?)(third party): also creates and manages virtual environments with a version-controlledPipfile. I’ve found this very simple to use.[docker](https://www.docker.com/resources/what-container?)containers: A container goes beyond a virtual environment, containing all the software and code needed to run an application (although it’s not quite a virtual machine). Docker is becoming more common in data science, because you can package together data, code, and all required libraries, so it’s worthwhile to learn how to set up and run docker containers.
(Real Python has great tutorials on all these tools).
pip freeze > requirements.txt is not good enough: you need to use virtual environments (which can be created from a requirements.txt) to ensure libraries match the expected version. A virtual env also has a specified version of Python removing the problem of different Python installs.
The approach you choose depends on the needs of your team and how much time you want to invest. For example, I use conda environments for personal work and pipenv at work. I’m not going to make a recommendation except to say: pick one and use it! You should never be doing data science without knowing the version of every library you call.
Inconsistent Code Style
If you had to make a choice of how many spaces to use on each line of a script, you’d have no time left over for thinking about the actual code! Most people’s formatting tendencies are not that bad, but they are close. You should never have to make conscious decisions about code format: things like spaces around keyword parameters, length of lines, blank lines between functions, trailing commas after the last item in a list, etc; factors dealing only with how the code looks.
Instead of making a choice on each line, make one global decision — adopt one style for your project — and never worry about it again. At work, my team uses the [black](https://black.readthedocs.io/en/stable/?) autoformatting tool which applies a standard code style across our entire project and just fixes the mistakes — no need to think about it. I have it set to auto-run every time I save a Python file in vscode. black works so well and is so easy to use that I use it for all my personal work as well.
There are other auto-formatting or linting options for Python and other languages. I’d suggest adopting a set of code style standards and using a tool to check all your files for usage. Spending more effort than required on code formatting is just a bad use of your precious time.
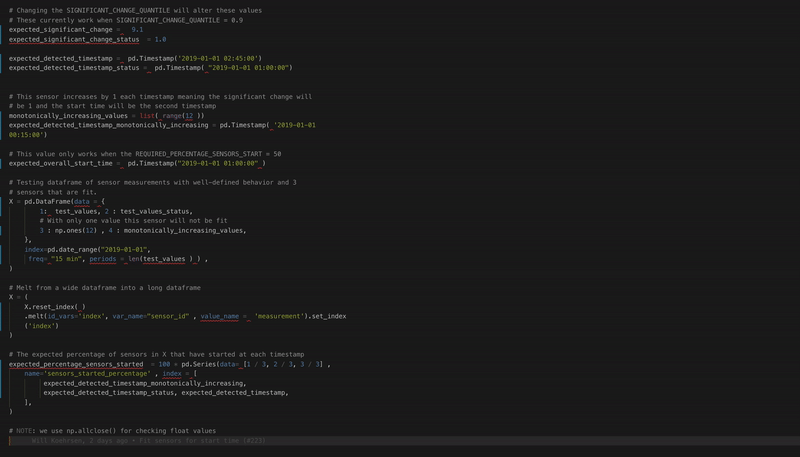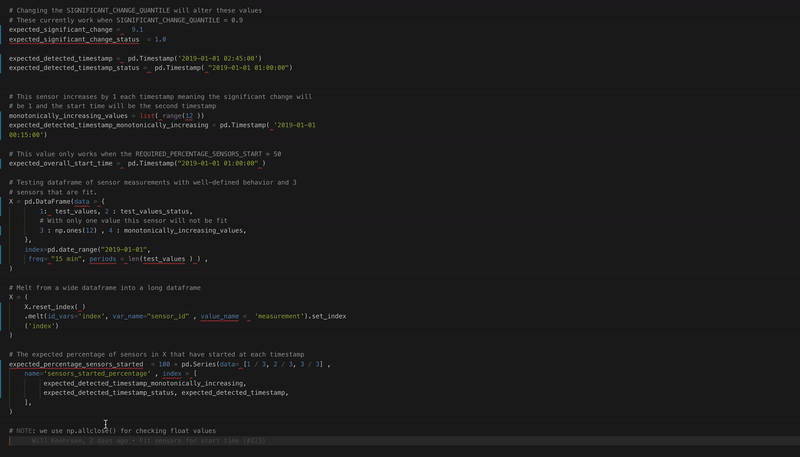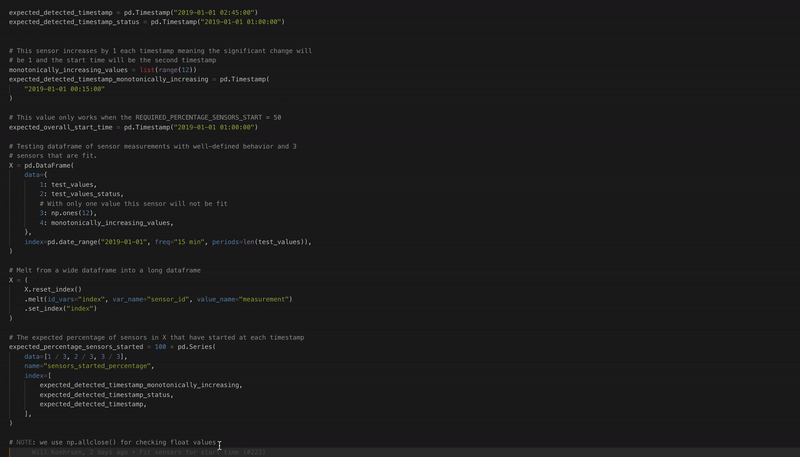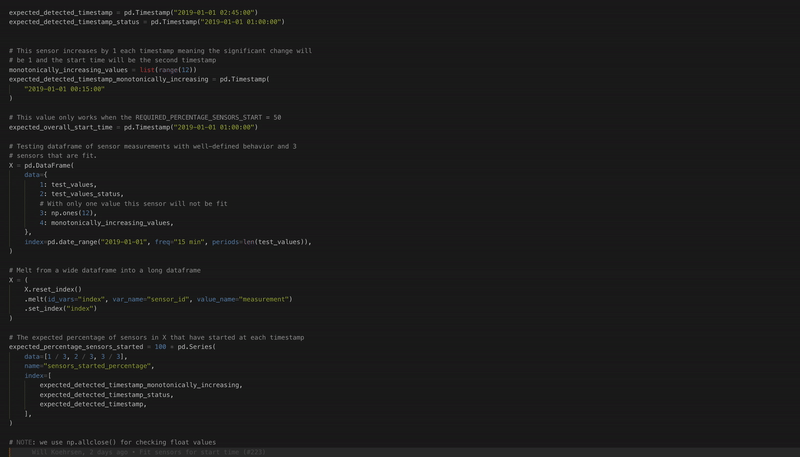 No more code format errors thanks to black autoformatting!
No more code format errors thanks to black autoformatting!
Inconsistent Naming Conventions
In another application of the “make a global decision once instead of many local decisions” idea, you should establish naming conventions for a project. These should cover variables, functions, classes, files, tests, and directories. Naming conventions should also include standardized abbreviations for units (such as kph ) and for aggregations ( min, max). I’ve written about naming variables here.
The choice of exact conventions does not matter as much using them consistently. Agree on standards across your whole team (which might just be you), write them down in a common location, and then follow them without deviation. At code reviews, (another crucial best practice) enforce the standards so everyone is on the same page. This tip is again about having to reduce the number of conscious decisions you make. When you are writing names for functions, variables, etc, there should be one very obvious choice based on the code and your conventions.
If you are struggling, adopt a standard convention used by another project. Don’t be dogmatic and refuse to change because you’ve always done things one way. There is no place for rigid, unchanging personal beliefs in programming. Make conventions, write them down, apply them, and stop spending time on the incidental problems of data science.
Different Development Environments across a Team
Everyone on your team should use the same development environment, no exclusions. As a lifelong (22 years) Windows user, I gave zero thought to protesting against using MacOS for development at my current position (Cortex Building Intelligence). There simply was no choice to make: everyone else uses a Mac, so that’s what I had to use for standardization across the team. I’m not going to advocate for one system over another (here are the numbers on which is the most used) but I will argue vociferously for everyone on the same team to use the same operating system.
“It worked on my machine” is the one statement no data scientist ever wants to hear. Even when using the same libraries, I’ve seen this problem because of different operating systems. Our team can be more productive when I know that an analysis I write on my machine will work on everyone else’s (thanks to the os and dependency management). Moreover, when anyone on our team needs to install new software, we can all use the same exact commands to do so. It’s not fun for the person who has to adopt a new operating system, but it’s necessary for the good of the team.
 Use the same operating system: no excuses
Use the same operating system: no excuses
Writing Too Much Code in Notebooks Instead of an Integrated Development Environment
Correcting this practice was probably the biggest change for me coming from a research data science background to industry: programs and individual scripts should be written in an integrated development environment, not Jupyter Notebooks. The notebook is great for exploration, learning, graphing, and literate programming, but you shouldn’t develop an unhealthy habit of depending on it for writing all code.
Jupyter Notebooks are a terrible place to write actual programs with many scripts because of the lack of tooling: no linting, no auto-formatting code across a project, poor file browsing, no project-wide find and replace, no built-in testing framework, poor debugging, no integrated terminal, and so on. No, Jupyter Lab does not solve these problems; it still is not a place where you can or should be developing scripts.
Breaking out of notebooks is intimidating because it requires you to hold larger pieces of information in your head at once. Instead of blocks of code, you need to think about code in terms of entire scripts consisting of many functions and classes. Moreover, a notebook presents a linear path of code executed from top to bottom, when a real program has many interlocking pieces that form a cycle. One script may import from 10 others in your module with pieces interacting in a complicated structure.
I don’t want to get into coding best practices, but the environment in which you develop has a massive impact on how you think about and write code. A proper integrated development environment gets you thinking about data science code not as isolated notebooks, but as a software product: one with many interlocking pieces and complicated interactions.
There are many great choices for an IDE. I recommend experimenting with a few to find the right complexity and number of features you need.
- Sublime Text starts lightweight but has many plug-ins
- Atom is another good basic IDE with packages for more functionality
- Rodeo tries to create an RStudio feel for Python
- PyCharm is a full-featured environment with way more features than you’ll ever need and a bit of a learning curve
Personally, I use Visual Studio Code, which has become the most popular editor for software engineers. vscode gives me everything mentioned above and more through extensions (including a built-in browser and git integration). I spend about 90% of my coding time within Visual Studio Code and I’ve come to like it just as much as the Jupyter Notebook.
There is nothing fundamentally wrong about Jupyter Notebooks, they just were never meant for developing serious programs. When used correctly (implementing the concept of literate programming) they are a great tool. However, as with any tool, notebooks can be used in places where they are not appropriate. When you want to start writing production code, you will have to switch to an integrated development environment. Even if you aren’t there yet, I’d recommend becoming familiar with the idea of writing scripts instead of notebooks and composing together many scripts into a library (which you can import into a notebook for analysis). Not using an IDE for developing programs is a serious obstacle: be nice to your working self and start using a full-featured programming environment.
 A little intimidating at first, but much more productive. Remember, your environment affects how you think.
A little intimidating at first, but much more productive. Remember, your environment affects how you think.
Conclusions
In his excellent paper “No Silver Bullet”, David Brooks discusses the idea of accidental vs essential problems in software engineering. The gains in productivity in software engineering over the past 40 years came about through the reduction of accidental problems — those related to translating ideas into code — and the essential difficulties — thinking up the ideas — remain. In data science, I still see many people struggling with incidental difficulties, tripping themselves up before they can even start coding because they don’t have a good environment or do not adhere to simple practices.
As a field, I think we can do better. Let’s spend less time on the accidental difficulties of data science — managing dependencies, code formatting, naming, operating systems, and code editors — and more time on the essential difficulties — developing algorithms, building models, engineering features, and deploying trained models (and fighting climate change with machine learning). By adopting the practices outlined in this article, you’ll have more time and mental resources to solve the problems that really matter.
As always, I welcome feedback and constructive criticism. I can be reached on Twitter @koehrsen_will.