
My Weaknesses as a Data Scientist
Without recognizing our weak points, we’ll never be able to overcome them
If modern job interviews have taught us anything, it’s that the correct answer to the question “What’s your biggest weakness?” is “I work too hard.” Clearly, it’d be ludicrous to actually talk about our weaknesses, right? Why would we want to mention what we can’t yet do? While job applications and LinkedIn profile pages don’t encourage us to disclose our weak points, if we never admit our deficiencies, then we can’t take the steps to address them.
The path to getting better in an endeavor is simple:
- Determine where you are now: identify weaknesses
- Figure out where you want to be: make a plan to get there
- Execute on the plan: take one small action at a time
We rarely get past the first step: especially in technical fields, we keep our heads down and continue working, using the skills we already have rather than attaining new ones that would make our jobs easier or open us up to new opportunities. Self-reflection — evaluating ourselves objectively — may seem like a foreign concept, but being able to take a step back and figuring out what we could do better or more efficiently is critical to advancing in any field.
With that in mind, I’ve tried to take an objective look at where I am now and identified 3 areas to work on to make me a better data scientist:
- Software engineering
- Scaling data science
- Deep learning
My purpose in writing this article about my weaknesses in data science is threefold. First, I genuinely care about getting better so I need to admit my weak points. By outlining my deficiencies and how I can address them, my objective is to keep myself motivated to follow through on my learning goals.
Second, I hope to encourage others to think about what skills they might not know and how they can work on acquiring them. You don’t have to write your own article disclosing what you don’t know, but taking a few moments to consider the question can pay off if you find a skill to work on.
Finally, I want to show you don’t need to know everything to be a successful data scientist. There are an almost unlimited number of data science/ machine learning topics, but a limited amount you can actually know. Despite what unrealistic job applications proclaim, you don’t need complete knowledge of every algorithm (or 5–10 years of experience) to be a practicing data scientist. Often, I hear from beginners who are overwhelmed by the number of topics they think they must learn and my advice is always the same: start with the basics and understand you don’t need to know it all!
 Even this is probably an exaggeration!
(Source)
Even this is probably an exaggeration!
(Source)
For each weakness, I’ve outlined the problem and what I’m currently doing to try and get better. Identifying one’s weaknesses is important, but so is forming a plan to address them. Learning a new skill takes time, but planning a series of small, concrete steps considerably increases your chances of success.
1. Software engineering
Having received my first real data science experience in an academic environment, I tried to avoid picking up a number of bad habits reflecting an academic way of doing data science. Among these are a tendency to write code that only runs once, a lack of documentation, difficult-to-read code without a consistent style, andhard coding specific values. All of these practices reflect one primary objective: develop a data science solution that works a single time for a specific dataset in order to write a paper.
As a prototypical example, our project worked with building energy data that initially came in 15-minute intervals. When we started getting data in 5-minute increments, we discovered our pipelines completely broke down because there were hundreds of places where the interval had been explicitly coded for 15 minutes. We couldn’t do a simple find and replace because this parameter was referred to by multiple names such as electricity_interval, timeBetweenMeasurements, or dataFreq. None of the researchers had given any thought to making the code easy to read or flexible to changing inputs.
In contrast, from a software engineering point of view, code must be extensively tested with many different inputs, well-documented, work within an existing framework, and adhere to coding standards so it can be understood by other developers. Despite my best intentions, I still occasionally write code like a data scientist instead of like a software engineer. I’ve started to think what separates the average from the great data scientists is writing code using software engineering best practices — your model won’t be deployed if it’s not robust or doesn’t fit within an architecture— and now I’m trying to train myself to think like a computer scientist.
What I’m doing
As usual, there’s no better method to learn technical skills than practice. Fortunately, at my current job, I’m able to make contributions both to our internal tooling as well as an open-source library (Featuretools). This has forced me to learn a number of practices including:
- Writing unit tests
- Following a coding style guide
- Writing functions that accept changing parameters
- Documenting code thoroughly
- Having code reviewed by others
- Refactoring code to make it simpler and easier to read
Even for those data scientists not yet at a company, you can get experience with many of these by working on collaborative open-source projects. Another great way to figure out solid coding practices is to read through source code for popular libraries on GitHub (Scikit-Learn is one of my favorites). Having feedback from others is critical, so find a community and seek out advice from those more experienced than yourself.
Thinking like a software engineer requires a change in mindset, but adopting these practices is not difficult if you’re able to slow down and keep them in mind. For example, anytime I find myself copying and pasting code in a Jupyter Notebook and changing a few values, I try to stop and realize I’d be better off using a function which, in the long run, makes me more efficient. While I’m nowhere near perfect on these practices, I’ve found they not only make it easier for others to read my code, they make it easier for me to build on my work. Code is going to be read more than it’s written, and that includes by your future self who will appreciate documentation and a consistent style.
When I’m not writing code that is designed to be part of a larger library, I still try to use some of these methods. Writing unit tests for a data analysis may seem strange to a data scientist, but it’s great practice for when you actually need to develop tests to ensure your code works as intended. Also, there are many linting tools that check your code follows a coding style (I still struggle with the no spaces around keyword arguments).
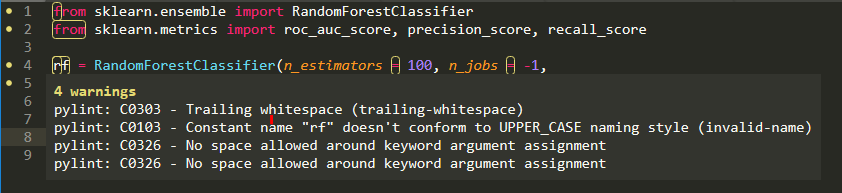 Always things to improve (using pylint in Sublime Text 3).
Always things to improve (using pylint in Sublime Text 3).
There are many other aspects of computer science I’d like to work on such as writing efficient implementations rather than brute force methods (for example using vectorization instead of looping). However, it’s also important to realize you can’t change everything all at once, which is why I’m focusing on a few practices and making them habits built into my workflows.
While data science is now its own field, practitioners can benefit by adapting best practices from existing fields such as software engineering.
2. Scaling Data Science
Although you can teach yourself everything in data science, there are some limits to what you can put into practice. One is the difficulty in scaling an analysis or a predictive model to large datasets. Most of us don’t have access to a computing cluster and don’t want to put up money for a personal supercomputer. This means that when we learn new methods, we tend to apply them to small, well-behaved datasets.
Unfortunately, in the real world, datasets do not adhere to strict size or cleanliness limits and you are going to need different approaches to solve problems. First of all, you probably will need to break out of the safe confines of a personal computer and use a remote instance — such as through AWS EC2 — or even multiple machines. This means learning how to connect to remote machines and mastering the command line — you won’t have access to a mouse and a gui on your EC2 instance.
When learning data science, I tried to do work on EC2 machines, either with the free tier or free credits (you can create multiple accounts if you manage all the emails and passwords). This helped get me familiar with the command line, however ,I still didn’t tackle a second issue: datasets that are larger than the memory of the machine. Lately, I’ve realized this is a limitation holding me back, and it’s time to learn how to handle larger datasets.
What I’m Doing
Even without spending thousands of dollars on computing resources, it is possible to practice the methods of working with datasets that don’t fit in memory. Some of these include iterating through a dataset one chunk at a time, breaking one large dataset into many smaller pieces, or with tools like Dask that handle the details of working with large data for you.
My current approach, both on internal projects and open-source datasets, is to partition a dataset into subsets, develop a pipeline that can handle one partition, and then use Dask or Spark with PySpark to run the subsets through the pipeline in parallel. This approach doesn’t require a supercomputer or a cluster — you can parallelize operations on a personal machine using multiple cores. Then, when you have access to more resources, you can adapt the same workflow to scale up.
Also, thanks to data repositories such as Kaggle, I’ve been able to find some extremely large datasets and read through other data scientist’s approaches to working with them. I’ve picked up a number of useful tips such as reducing memory consumption by changing the data type in a dataframe. These approaches help make me more efficient with datasets of any size.
While I haven’t yet had to tackle massive terabyte-scale datasets, these approaches have helped me learn basic strategies of working with large data. For some recent projects, I was able to apply the skills I learned so far to do analysis on a cluster running on AWS. Over the coming months, I hope to gradually increase the size of datasets I’m comfortable analyzing. It’s a pretty safe bet that datasets are not going to decrease in size and I know I’ll need to continue leveling up my skills for handling larger quantities of data.
 The US Library of Congress “only” has about 3 Petabytes of material. (Image source)
The US Library of Congress “only” has about 3 Petabytes of material. (Image source)
3. Deep Learning
Although artificial intelligence has gone through periods of boom and bust in the past, recent successes in fields such as computer vision, natural language processing, and deep reinforcement learning have convinced me deep learning — using multi-layered neural networks — is not another passing fad.
Unlike with software engineering or scaling data science, my current position doesn’t require any deep learning: traditional machine learning techniques (e.g. Random Forest) have been more than capable of solving all our customer’s problems. However, I recognize that not every dataset will be structured in neat rows and columns and neural networks are the best option (at the moment) to take on projects with text or images. I could keep exploiting my current skills on the problems I’ve always solved, but, especially early in my career, exploring topics is an exercise with great potential value.
 The Explore/Exploit Tradeoff applies to reinforcement learning and your life!
(Source)
The Explore/Exploit Tradeoff applies to reinforcement learning and your life!
(Source)
There are many different subfields within deep learning and it’s hard to figure out which methods or libraries will eventually win out. Nonetheless, I think that a familiarity with the field and being confident implementing some of the techniques will allow one to approach a wider range of problems. Given that solving problems is what drove me to data science, adding the tools of deep learning to my toolbox is a worthwhile investment.
What I’m Doing
My plan for studying deep learning is the same as the approach I applied to turning myself into a data scientist:
- Read books and tutorials that emphasize implementations
- Practice the techniques and methods on realistic projects
- Share and explain my projects through writing
When studying a technical topic, an effective approach is to learn by doing. For me this means starting not with the underlying, fundamental theory, but by finding out how to implement the methods to solve problems. This top-down approach means I place a lot of value on books that have a hands-on style, namely those with many code examples. After I see how the technique works, then I go back to the theory so I can use the methods more effectively.
Although I may be on my own because I don’t have the opportunity to learn neural networks from others at work, in data science, you’re never truly on your own because of the abundance of resources and the extensive community. For deep learning I’m relying primarily on three books:
- Deep Learning Cookbook by Douwe Osinga
- Deep Learning with Python by Francois Chollet
- Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
The first two emphasis building actual solutions with neural networks while the third covers the theory in depth. When reading about technical topics make it an active experience: whenever possible, get your hands on the keyboard coding along with what you read. Books like the first two that provide code samples are great: often I’ll type an example line-by-line into a Jupyter Notebook to figure out how it works and write detailed notes as I go.
Furthermore, I try not just to copy the code examples, but to experiment with them or adapt them to my own project. An application of this is my recent work with building a book recommendation system, a project adapted from a similar code exercise in the Deep Learning Cookbook. It can be intimidating trying to start your own project from scratch, and, when you need a boost, there is nothing wrong with building on what others have done.
Finally, one of the most effective ways to learn a topic is by teaching it to others. From experience, I don’t fully comprehend a concept until I try to explain it to someone else in simple terms. With each new topic I cover in deep learning, I’ll keep writing, sharing both the technical implementation details along with a conceptual explanation.
Teaching is one of the best ways to learn, and I plan on making it an integral part of my quest to study deep learning.
 From personal experience, this looks accurate
(Source)
From personal experience, this looks accurate
(Source)
Conclusions
It may feel a little strange proclaiming your weaknesses. I know writing this article made me uncomfortable, but I’m putting it out because it will eventually make me a better data scientist. Moreover, I’ve found that many people, employers included, are impressed if you have the self-awareness to admit shortcomings and discuss how you will address them.
A lack of skills is not a weakness — the real shortcoming is pretending you know everything and have no need for getting better.
By identifying my data science weaknesses — software engineering, scaling analysis/modeling, deep learning — I aim to improve myself, encourage others to think about their weaknesses, and show that you don’t need to learn everything to be a successful data scientist. While reflecting on one’s weak points can be painful, learning is enjoyable: one of the most rewarding experiences is looking back after a sustained period of studying and realizing you know more than you did before you started.
As always, I welcome feedback and constructive criticism. I can be reached on Twitter @koehrsen_will or through my personal website willk.online.