
Wikipedia Data Science: Working with the World’s Largest Encyclopedia
How to programmatically download and parse the Wikipedia
Wikipedia is one of modern humanity’s most impressive creations. Who would have thought that in just a few years, anonymous contributors working for free could create the greatest source of online knowledge the world has ever seen? Not only is Wikipedia the best place to get information for writing your college papers, but it’s also an extremely rich source of data that can fuel numerous data science projects from natural language processing to supervised machine learning.
The size of Wikipedia makes it both the world’s largest encyclopedia and slightly intimidating to work with. However, size is not an issue with the right tools, and in this article, we’ll walk through how we can programmatically download and parse through all of the English language Wikipedia.
Along the way, we’ll cover a number of useful topics in data science:
- Finding and programmatically downloading data from the web
- Parsing web data (HTML, XML, MediaWiki) using Python libraries
- Running operations in parallel with multiprocessing/multithreading
- Benchmarking methods to find the optimal solution to a problem
The original impetus for this project was to collect information on every single book on Wikipedia, but I soon realized the solutions involved were more broadly applicable. The techniques covered here and presented in the accompanying Jupyter Notebook will let you efficiently work with any articles on Wikipedia and can be extended to other sources of web data.
The notebook containing the Python code for this article is available on GitHub. This project was inspired by the excellent Deep Learning Cookbook by Douwe Osinga and much of the code is adapted from the book. The book is well worth it and you can access the Jupyter Notebooks at no cost on GitHub.
Finding and Downloading Data Programmatically
The first step in any data science project is accessing your data! While we could make individual requests to Wikipedia pages and scrape the results, we’d quickly run into rate limits and unnecessarily tax Wikipedia’s servers. Instead, we can access a dump of all of Wikipedia through Wikimedia at dumps.wikimedia.org. (A dump refers to a periodic snapshot of a database).
The English version is at dumps.wikimedia.org/enwiki. We view the available versions of the database using the following code.
import requests
# Library for parsing HTML
from bs4 import BeautifulSoup
base_url = 'https://dumps.wikimedia.org/enwiki/'
index = requests.get(base_url).text
soup_index = BeautifulSoup(index, 'html.parser')
# Find the links on the page
dumps = [a['href'] for a in soup_index.find_all('a') if
a.has_attr('href')]
dumps
['../',
'20180620/',
'20180701/',
'20180720/',
'20180801/',
'20180820/',
'20180901/',
'20180920/',
'latest/']
This code makes use of the BeautifulSoup library for parsing HTML. Given that HTML is the standard markup language for web pages, this is an invaluable library for working with web data.
For this project, we’ll take the dump on September 1, 2018 (some of the dumps are incomplete so make sure to choose one with the data you need). To find all the available files in the dump, we use the following code:
dump_url = base_url + '20180901/'
# Retrieve the html
dump_html = requests.get(dump_url).text
# Convert to a soup
soup_dump = BeautifulSoup(dump_html, 'html.parser')
# Find list elements with the class file
soup_dump.find_all('li', {'class': 'file'})[:3]
[<li class="file"><a href="/enwiki/20180901/enwiki-20180901-pages-articles-multistream.xml.bz2">enwiki-20180901-pages-articles-multistream.xml.bz2</a> 15.2 GB</li>,
<li class="file"><a href="/enwiki/20180901/enwiki-20180901-pages-articles-multistream-index.txt.bz2">enwiki-20180901-pages-articles-multistream-index.txt.bz2</a> 195.6 MB</li>,
<li class="file"><a href="/enwiki/20180901/enwiki-20180901-pages-meta-history1.xml-p10p2101.7z">enwiki-20180901-pages-meta-history1.xml-p10p2101.7z</a> 320.6 MB</li>]
Again, we parse the webpage using BeautifulSoup to find the files. We could go to https://dumps.wikimedia.org/enwiki/20180901/ and look for the files to download manually, but that would be inefficient. Knowing how to parse HTML and interact with websites in a program is an extremely useful skill considering how much data is on the web. Learn a little web scraping and vast new data sources become accessible. (Here’s a tutorial to get you started).
Deciding what to Download
The above code finds all of the files in the dump. This includes several options for download: the current version of only the articles, the articles along with the current discussion, or the articles along with all past edits and discussion. If we go with the latter option, we are looking at several terabytes of data! For this project, we’ll stick to the most recent version of only the articles. This page is useful for determining which files to get given your needs.
The current version of all the articles is available as a single file. However, if we get the single file, then when we parse it, we’ll be stuck going through all the articles sequentially — one at a time — a very inefficient approach. A better option is to download partitioned files, each of which contains a subset of the articles. Then, as we’ll see, we can parse through multiple files at a time through parallelization, speeding up the process significantly.
When I’m dealing with files, I would rather have many small files than one large file because then I can parallelize operations on the files.
The partitioned files are available as bz2-compressed XML (eXtended Markup Language). Each partition is around 300–400 MB in size with a total compressed size of 15.4 GB. We won’t need to decompress the files, but if you choose to do so, the entire size is around 58 GB. This actually doesn’t seem too large for all of human knowledge! (Okay, not all knowledge, but still).
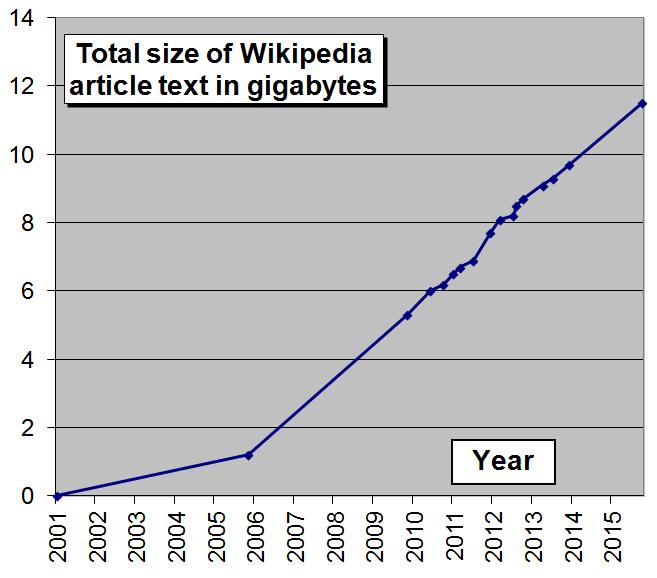 Compressed Size of Wikipedia (Source).
Compressed Size of Wikipedia (Source).
{kind=link}
Downloading Files
To actually download the files, the Keras utility get_file is extremely useful. This downloads a file at a link and saves it to disk.
from keras.utils import get_file
saved_file_path = get_file(file, url)
The files are saved in ~/.keras/datasets/, the default save location for Keras. Downloading all of the files one at a time takes a little over 2 hours. (You can try to download in parallel, but I ran into rate limits when I tried to make multiple requests at the same time.)
Parsing the Data
It might seem like the first thing we want to do is decompress the files. However, it turns out we won’t ever actually need to do this to access all the data in the articles! Instead, we can iteratively work with the files by decompressing and processing lines one at a time. Iterating through files is often the only option if we work with large datasets that do not fit in memory.
To iterate through a bz2 compressed file we could use the bz2 library. In testing though, I found that a faster option (by a factor of 2) is to call the system utility bzcat with the subprocess Python module. This illustrates a critical point: often, there are multiple solutions to a problem and the only way to find what is most efficient is to benchmark the options. This can be as simple as using the %%timeit Jupyter cell magic to time the methods.
For the complete details, see the notebook, but the basic format of iteratively decompressing a file is:
data_path = '~/.keras/datasets/enwiki-20180901-pages-articles15.xml-p7744803p9244803.bz2
# Iterate through compressed file one line at a time
for line in subprocess.Popen(['bzcat'],
stdin = open(data_path),
stdout = subprocess.PIPE).stdout:
# process line
If we simply read in the XML data and append it to a list, we get something that looks like this:
 Raw XML from Wikipedia Article.
Raw XML from Wikipedia Article.
This shows the XML from a single Wikipedia article. The files we have downloaded contain millions of lines like this, with thousands of articles in each file. If we really wanted to make things difficult, we could go through this using regular expressions and string matching to find each article. Given this is extraordinarily inefficient, we’ll take a better approach using tools custom built for parsing both XML and Wikipedia-style articles.
Parsing Approach
We need to parse the files on two levels:
- Extract the article titles and text from the XML
- Extract relevant information from the article text
Fortunately, there are good options for both of these operations in Python.
Parsing XML
To solve the first problem of locating articles, we’ll use the SAX parser, which is “The Simple API for XML.” BeautifulSoup can also be used for parsing XML, but this requires loading the entire file into memory and building a Document Object Model (DOM). SAX, on the other hand, processes XML one line at a time, which fits our approach perfectly.
The basic idea we need to execute is to search through the XML and extract the information between specific tags (If you need an introduction to XML, I’d recommend starting here). For example, given the XML below:
<title>Carroll F. Knicely</title>
<text xml:space="preserve">\'\'\'Carroll F. Knicely\'\'\' (born c. 1929 in [[Staunton, Virginia]] - died November 2, 2006 in [[Glasgow, Kentucky]]) was [[Editing|editor]] and [[Publishing|publisher]] of the \'\'[[Glasgow Daily Times]]\'\' for nearly 20 years (and later, its owner) and served under three [[Governor of Kentucky|Kentucky Governors]] as commissioner and later Commerce Secretary.\n'
</text>
We want to select the content between the <title> and <text> tags. (The title is simply the Wikipedia page title and the text is the content of the article). SAX will let us do exactly this using a parser and a ContentHandler which controls how the information passed to the parser is handled. We pass the XML to the parser one line at a time and the Content Handler lets us extract the relevant information.
This is a little difficult to follow without trying it out yourself, but the idea is that the Content handler looks for certain start tags, and when it finds one, it adds characters to a buffer until it encounters the same end tag. Then it saves the buffer content to a dictionary with the tag as the key. The result is that we get a dictionary where the keys are the tags and the values are the content between the tags. We can then send this dictionary to another function that will parse the values in the dictionary.
The only part of SAX we need to write is the Content Handler. This is shown in its entirety below:
In this code, we are looking for the tags title and text . Every time the parser encounters one of these, it will save characters to the buffer until it encounters the same end tag (identified by </tag>). At this point it will save the buffer contents to a dictionary — self._values . Articles are separated by <page> tags, so if the content handler encounters an ending </page> tag, then it should add the self._values to the list of articles, self._pages. If this is a little confusing, then perhaps seeing it in action will help.
The code below shows how we use this to search through the XML file to find articles. For now we’re just saving them to the handler._pages attribute, but later we’ll send the articles to another function for parsing.
# Object for handling xml
handler = WikiXmlHandler()
# Parsing object
parser = xml.sax.make_parser()
parser.setContentHandler(handler)
# Iteratively process file
for line in subprocess.Popen(['bzcat'],
stdin = open(data_path),
stdout = subprocess.PIPE).stdout:
parser.feed(line)
# Stop when 3 articles have been found
if len(handler._pages) > 2:
break
If we inspect handler._pages , we’ll see a list, each element of which is a tuple with the title and text of one article:
handler._pages[0]
[('Carroll Knicely',
"'''Carroll F. Knicely''' (born c. 1929 in [[Staunton, Virginia]] - died November 2, 2006 in [[Glasgow, Kentucky]]) was [[Editing|editor]] and [[Publishing|publisher]] ...)]
At this point we have written code that can successfully identify articles within the XML. This gets us halfway through the process of parsing the files and the next step is to process the articles themselves to find specific pages and information. Once again, we’ll turn to a tool purpose built for the task.
Parsing Wikipedia Articles
Wikipedia runs on a software for building wikis known as MediaWiki. This means that articles follow a standard format that makes programmatically accessing the information within them simple. While the text of an article may look like just a string, it encodes far more information due to the formatting. To efficiently get at this information, we bring in the powerful mwparserfromhell , a library built to work with MediaWiki content.
If we pass the text of a Wikipedia article to the mwparserfromhell , we get a Wikicode object which comes with many methods for sorting through the data. For example, the following code creates a wikicode object from an article (about KENZ FM) and retrieves the wikilinks() within the article. These are all of the links that point to other Wikipedia articles:
import mwparserfromhell
# Create the wiki article
wiki = mwparserfromhell.parse(handler._pages[6][1])
# Find the wikilinks
wikilinks = [x.title for x in wiki.filter_wikilinks()]
wikilinks[:5]
['Provo, Utah', 'Wasatch Front', 'Megahertz', 'Contemporary hit radio', 'watt']
There are a number of useful methods that can be applied to the wikicode such as finding comments or searching for a specific keyword. If you want to get a clean version of the article text, then call:
wiki.strip_code().strip()
'KENZ (94.9 FM, " Power 94.9 " ) is a top 40/CHR radio station broadcasting to Salt Lake City, Utah '
Since my ultimate goal was to find all the articles about books, the question arises if there is a way to use this parser to identify articles in a certain category? Fortunately, the answer is yes, using MediaWiki templates.
Article Templates
Templates are standard ways of recording information. There are numerous templates for everything on Wikipedia, but the most relevant for our purposes are Infoboxes . These are templates that encode summary information for an article. For instance, the infobox for War and Peace is:
 War and Peace Infobox book template
War and Peace Infobox book template
Each category of articles on Wikipedia, such as films, books, or radio stations, has its own type of infobox. In the case of books, the infobox template is helpfully named Infobox book. Just as helpful, the wiki object has a method called filter_templates() that allows us to extract a specific template from an article. Therefore, if we want to know whether an article is about a book, we can filter it for the book infobox. This is shown below:
# Filter article for book template
wiki.filter_templates('Infobox book')
If there’s a match, then we’ve found a book! To find the Infobox template for the category of articles you are interested in, refer to the list of infoboxes.
How do we combine the mwparserfromhell for parsing articles with the SAX parser we wrote? Well, we modify the endElement method in the Content Handler to send the dictionary of values containing the title and text of an article to a function that searches the article text for specified template. If the function finds an article we want, it extracts information from the article and then returns it to the handler. First, I’ll show the updated endElement :
def endElement(self, name):
"""Closing tag of element"""
if name == self._current_tag:
self._values[name] = ' '.join(self._buffer)
if name == 'page':
self._article_count += 1
# Send the page to the process article function
book = process_article(**self._values,
template = 'Infobox book')
# If article is a book append to the list of books
if book:
self._books.append(book)
Now, once the parser has hit the end of an article, we send the article on to the function process_article which is shown below:
Although I’m looking for books, this function can be used to search for any category of article on Wikipedia. Just replace the template with the template for the category (such as Infobox language to find languages) and it will only return the information from articles within the category.
We can test this function and the new ContentHandler on one file.
Searched through 427481 articles. Found 1426 books in 1055 seconds.
Let’s take a look at the output for one book:
['War and Peace',
{'name': 'War and Peace',
'author': 'Leo Tolstoy',
'language': 'Russian, with some French',
'country': 'Russia',
'genre': 'Novel (Historical novel)',
'publisher': 'The Russian Messenger (serial)',
'title_orig': 'Война и миръ',
'orig_lang_code': 'ru',
'translator': 'The first translation of War and Peace into English was by American Nathan Haskell Dole, in 1899',
'image': 'Tolstoy - War and Peace - first edition, 1869.jpg',
'caption': 'Front page of War and Peace, first edition, 1869 (Russian)',
'release_date': 'Serialised 1865–1867; book 1869',
'media_type': 'Print',
'pages': '1,225 (first published edition)'},
['Leo Tolstoy',
'Novel',
'Historical novel',
'The Russian Messenger',
'Serial (publishing)',
'Category:1869 Russian novels',
'Category:Epic novels',
'Category:Novels set in 19th-century Russia',
'Category:Russian novels adapted into films',
'Category:Russian philosophical novels'],
['https://books.google.com/?id=c4HEAN-ti1MC',
'https://www.britannica.com/art/English-literature',
'https://books.google.com/books?id=xf7umXHGDPcC',
'https://books.google.com/?id=E5fotqsglPEC',
'https://books.google.com/?id=9sHebfZIXFAC'],
'2018-08-29T02:37:35Z']
For every single book on Wikipedia, we have the information from the Infobox as a dictionary, the internal wikilinks, the external links, and the timestamp of the most recent edit. (I’m concentrating on these pieces of information to build a book recommendation system for my next project). You can modify the process_article function and WikiXmlHandler class to find whatever information and articles you need!
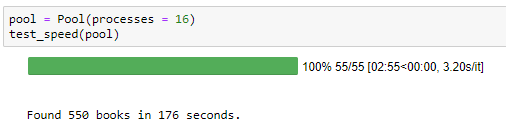
If you look at the time to process just one file, 1055 seconds, and multiply that by 55, you get over 15 hours of processing time for all files! Granted, we could just run that overnight, but I’d rather not waste the extra time if I don’t have to. This brings us to our final technique we’ll cover in this project: parallelization using multiprocessing and multithreading.
Running Operations in Parallel
Instead of parsing through the files one at a time, we want to process several of them at once (which is why we downloaded the partitions). We can do this using parallelization, either through multithreading or multiprocessing.
Multithreading and Multiprocessing
Multithreading and multiprocessing are ways to carry out many tasks on a computer — or multiple computers — simultaneously. We many files on disk, each of which needs to be parsed in the same way. A naive approach would be to parse one file at a time, but that is not taking full advantage of our resources. Instead, we use either multithreading or multiprocessing to parse many files at the same time, significantly speeding up the entire process.
Generally, multithreading works better (is faster) for input / output bound tasks, such as reading in files or making requests. Multiprocessing works better (is faster) for cpu-bound tasks (source). For the process of parsing articles, I wasn’t sure which method would be optimal, so again I benchmarked both of them with different parameters.
Learning how to set up tests and seek out different ways to solve a problem will get you far in a data science or any technical career.
(The code for testing multithreading and multiprocessing appears at the end of the notebook). When I ran the tests, I found multiprocessing was almost 10 times faster indicating this process is probably CPU bound (limited).
| Multiprocessing Results | Multithreading Results |
|---|---|
 |
 |
Learning multithreading / multiprocessing is essential for making your data science workflows more efficient. I’d recommend this article to get started with the concepts. (We’ll stick to the built-in multiprocessing library, but you can also using Dask for parallelization as in this project).
After running a number of tests, I found the fastest way to process the files was using 16 processes, one for each core of my computer. This means we can process 16 files at a time instead of 1! I’d encourage anyone to test out a few options for multiprocessing / multithreading and let me know the results! I’m still not sure I did things in the best way, and I’m always willing to learn.
Setting Up Parallelized Code
To run an operation in parallel, we need a service and a set of tasks . A service is just a function and tasks are in an iterable — such as a list — each of which we send to the function. For the purpose of parsing the XML files, each task is one file, and the function will take in the file, find all the books, and save them to disk. The pseudo-code for the function is below:
def find_books(data_path, save = True):
"""Find and save all the book articles from a compressed
wikipedia XML file. """
# Parse file for books
if save:
# Save all books to a file based on the data path name
The end result of running this function is a saved list of books from the file sent to the function. The files are saved as json, a machine readable format for writing nested information such as lists of lists and dictionaries. The tasks that we want to send to this function are all the compressed files.
# List of compressed files to process
partitions = [keras_home + file for file in os.listdir(keras_home) if 'xml-p' in file]
len(partitions), partitions[-1]
(55, '/home/ubuntu/.keras/datasets/enwiki-20180901-pages-articles17.xml-p11539268p13039268.bz2')
For each file, we want to send it to find_books to be parsed.
Searching through all of Wikipedia
The final code to search through every article on Wikipedia is below:
from multiprocessing import Pool
# Create a pool of workers to execute processes
pool = Pool(processes = 16)
# Map (service, tasks), applies function to each partition
results = pool.map(find_books, partitions)
pool.close()
pool.join()
We map each task to the service, the function that finds the books (map refers to applying a function to each item in an iterable). Running with 16 processes in parallel, we can search all of Wikipedia in under 3 hours! After running the code, the books from each file are saved on disk in separate json files.
Reading and Joining Files with Multithreading
For practice writing parallelized code, we’ll read the separate files in with multiple processes, this time using threads. The multiprocessing.dummy library provides a wrapper around the threading module. This time the service is read_data and the tasks are the saved files on disk:
The multithreaded code works in the exact same way, mapping tasks in an iterable to function. Once we have the list of lists, we flatten it to a single list.
print(f'Found {len(book_list)} books.')
__Found 37861 books.__
Wikipedia has nearly 38,000 articles on books according to our count. The size of the final json file with all the book information is only about 55 MB meaning we searched through over 50 GB (uncompressed) of total files to find 55 MB worth of books! Given that we are only keeping a limited subset of the book information, that makes sense.
We now have information on every single book on Wikipedia. You can use the same code to find articles for any category of your choosing, or modify the functions to search for different information. Using some fairly simple Python code, we are able to search through an incredible amount of information.
 Size of Wikipedia if printed in volumes (Source).
Size of Wikipedia if printed in volumes (Source).
Conclusions
In this article, we saw how to download and parse the entire English language version of Wikipedia. Having a ton of data is not useful unless we can make sense of it, and so we developed a set of methods for efficiently processing all of the articles for the information we need for our projects.
Throughout this project, we covered a number of important topics:
- Finding and downloading data programmatically
- Parsing through data in an efficient manner
- Running operations in parallel to get the most from our hardware
- Setting up and running benchmarking tests to find efficient solutions
The skills developed in this project are well-suited to Wikipedia data but are also broadly applicable to any information from the web. I’d encourage you to apply these methods for your own projects or try analyzing a different category of articles. There’s plenty of information for everyone to do their own project! (I am working on making a book recommendation system with the Wikipedia articles using entity embeddings from neural networks.)
Wikipedia is an incredible source of human-curated information, and we now know how to use this monumental achievement by accessing and processing it programmatically. I look forward to writing about and doing more Wikipedia Data Science. In the meantime, the techniques presented here are broadly applicable so get out there and find a problem to solve!
As always, I welcome feedback and constructive criticism. I can be reached on Twitter @koehrsen_will or on my personal website at willk.online.