
Lessons From How To Lie With Statistics

Timeless Data Literacy Advice
How to Lie With Statistics is a 65-year-old book that can be read in an hour and will teach you more practical information you can use every day than any book on “big data” or “deep learning.” For all promised by machine learning and petabyte-scale data, the most effective techniques in data science are still small tables, graphs, or even a single number that summarize a situation and help us — or our bosses — make a decision informed by data.
Time and again, I’ve seen thousands of work hours on complex algorithms summarized in a single number. Ultimately, that’s how the biggest decisions are made: with a few pieces of data a human can process. This is why lessons from “How to Lie with Statistics” (by Darell Huff) are relevant even though each of us probably generates more data in a single day than existed in the entire world at the writing of the book. As producers of tables and graphs, we need to effectively present valid summaries. As consumers of information, we need to spot misleading/exaggerated statistics which manipulate us to take action that benefits someone else at our expense.
These skills fall under a category called “data literacy”: the ability to read, understand, argue with, and make decisions from information. Compared to algorithms or big data processing, data literacy may not seem exciting, but it should form the basis for any data science education. Fortunately, these core ideas don’t change much over time and often the best books on the subject (such as The Visual Display of Quantitative Information) are decades old. The classic book discussed in this article addresses responsible consumption of data in a concise, effective, and enjoyable format. Here are my lessons learned from “How to Lie with Statistics” with commentary from my experiences.
 The Classis Book on Data Literacy: “How to Lie with Statistics” (Source)
The Classis Book on Data Literacy: “How to Lie with Statistics” (Source)
1. View Correlations with Skepticism
When two variables X and Y are correlated — meaning they increase together, decrease together, or one goes up as the other does down — there are four possible explanations:
A. X causes Y
B. Y causes X
C. A 3rd variable, Z, affects both X and Y
D. X and Y are completely unrelated
We often immediately jump to — or are led to believe — A or B when C or D may be as likely. For example, when we hear that more years of college education is positively correlated with a higher income, we conclude that additional years of university lead to greater wealth. However, it could also be a 3rd factor, such as willingness to work hard or parental income, is behind the increase in both more years of tertiary education and higher income. The 3rd hidden variable can lead us to incorrect conclusions about causality.
Other times two variables may appear to be correlated, but really have nothing to do with each other. If you make enough comparisons between datasets, you are bound to find some interesting relationships that look to move in sync. Tyler Vigen documents these at Spurious Correlations.
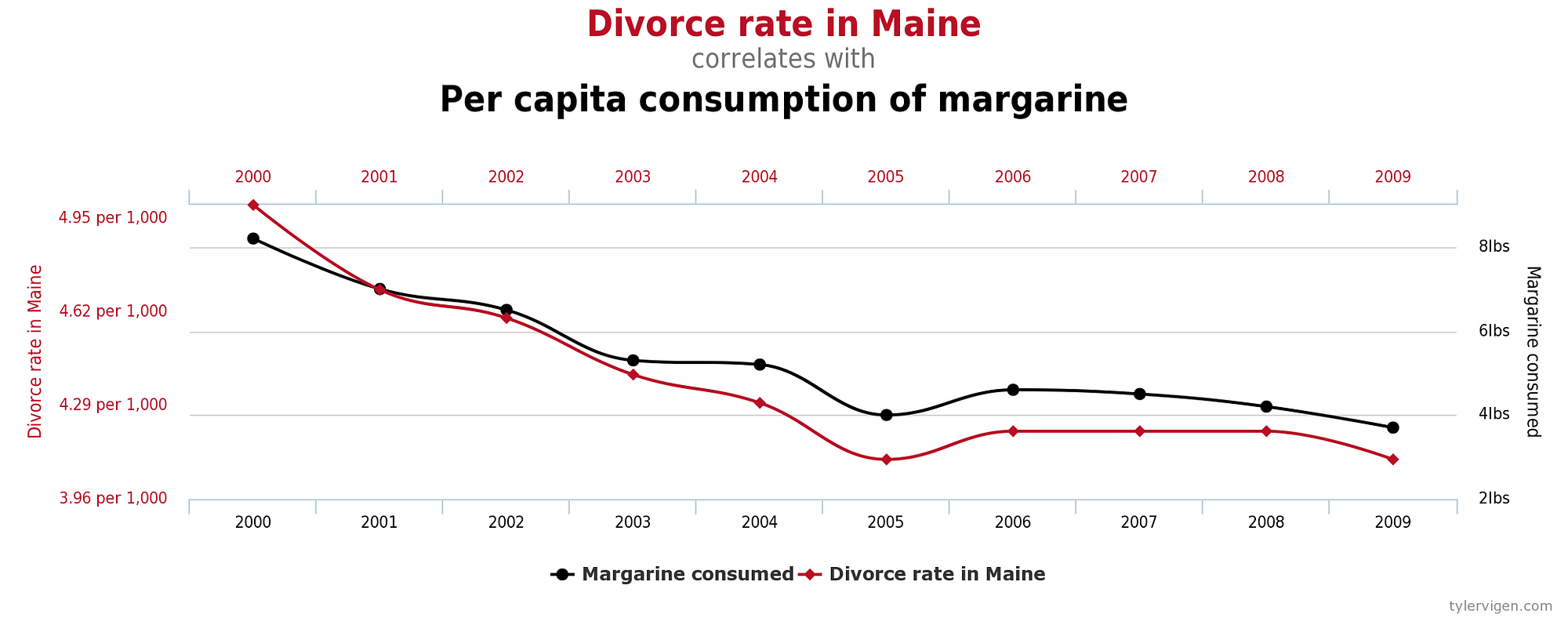 A Questionable Correlation (Source)
A Questionable Correlation (Source)
We’ve all heard the advice that correlation does not imply causation, but even when there is a causal effect, it’s often uncertain which way it goes. Does more praise of students from a teacher lead to higher grades? Do higher grades cause more praise? Or is there a third factor, smaller class sizes or more natural lighting in a class, causing both variables to increase? Questions of cause are answered by randomized controlled trials, not by observational studies where we cannot rule out additional factors that we do not measure. To avoid being misled, approach correlations between variables with skepticism by looking for confounding factors. Humans like neat, causal narratives, but that’s usually not what the data is telling us.
2. Relationships Don’t Last Forever
If you have successfully identified a correlation, don’t assume it lasts forever in either the positive or negative direction. Linear relationships are almost always only linear in a limited region of both variables. Beyond a point, the relationship may become logarithmic, completely disappear, or even reverse.
This can be observed in growth curves extrapolated over time. There are periods of linearity where growth occurs at a constant rate, but eventually, growth levels off because almost nothing continues growing indefinitely.
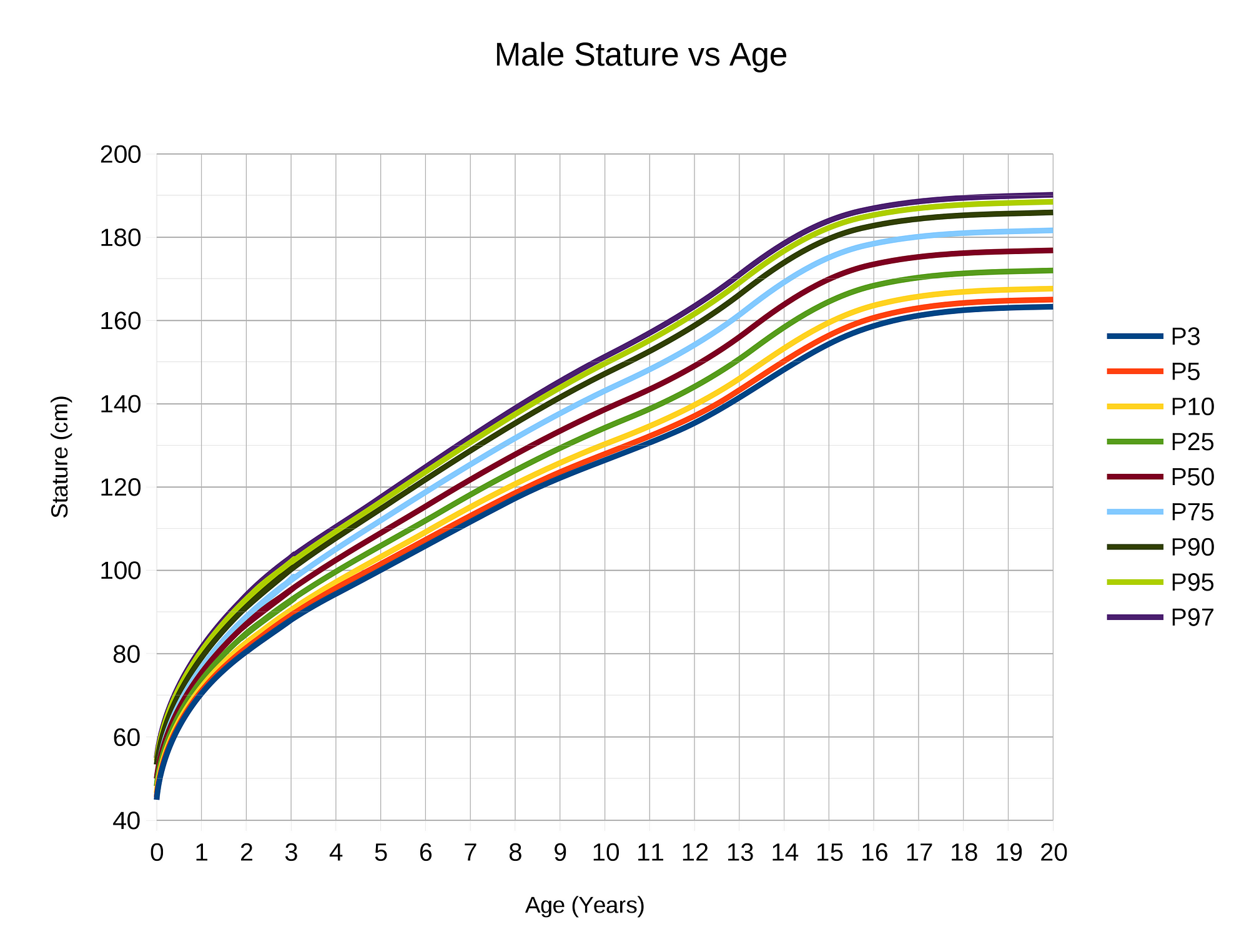 Male Height vs Age Showing Leveling Off of Growth Curve (Source).
Male Height vs Age Showing Leveling Off of Growth Curve (Source).
Extrapolating beyond the region of applicability for a relationship is known as a generalization error. You are taking a local phenomenon and trying to apply it globally. As people rise out of poverty, they tend to become more satisfied with life. However, once they hit a certain point (perhaps $75,000/year) happiness does not increase with wealth and may even decrease. This suggests there are diminishing returns to increasing wealth, just as there are in many aspects of human activity, like studying for a test.
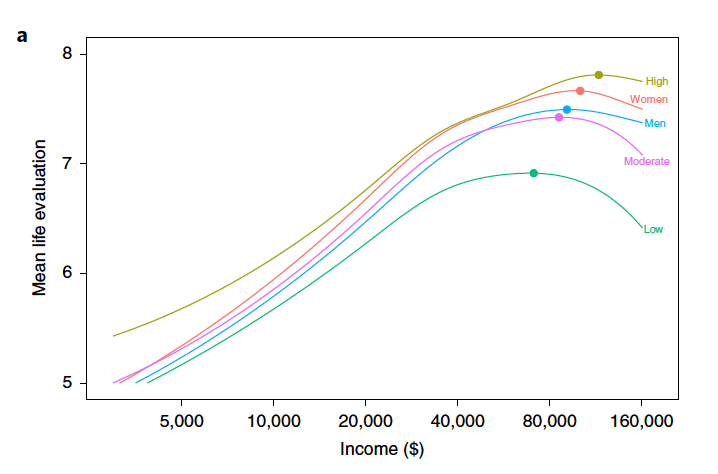 Happiness Increases with Wealth Up to a Certain Income Level (Source)
Happiness Increases with Wealth Up to a Certain Income Level (Source)
We see extrapolations all the time: growth rates for companies, population demographics, prices of stocks, national spending, etc. Oftentimes, people will use a valid relationship in one region to make a point about a region off the chart (for example claiming that $1 million/year will bring pure bliss). Remember, relationships in a local area do not always apply globally. Even if you have verified a causal relationship — or see one in a chart — make sure you don’t understand outside the limited region of validity.
3. Always Look at the Axes on a Chart
Adjusting the axes of a graph to make a point is a classic technique in manipulating charts. As a first principle, the y-axis on a bar chart should always start at 0. If not, it’s easy to prove an argument by manipulating the range, by for example, turning minor increases into massive changes:
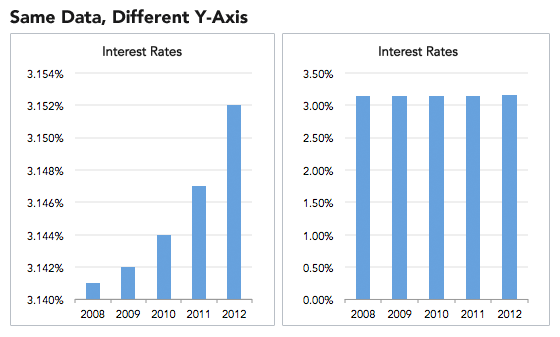 Misleading Graph That Does not start at 0 on the Y-Axes (Left) (Source)
Misleading Graph That Does not start at 0 on the Y-Axes (Left) (Source)
Another example of misleading graphs is y-axes with different scales. By carefully adjusting values, you produce surprising trends where none exist.
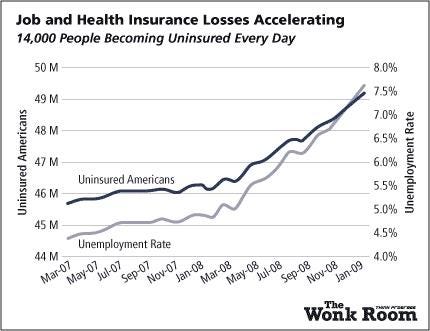 A Misleading Graph Creating An Extreme Trend Where There is Only a Small Increase (Source)
A Misleading Graph Creating An Extreme Trend Where There is Only a Small Increase (Source)
While this may seem like an obvious manipulation, advertisers and newspapers get away with it because people do not read information. Most people see a graph and immediately draw a conclusion from the shape of the lines or bars, exactly as the person who made the graph wants. To counter this, try reading axes values. A simple examination may tell you changes are not as big as they look and trends have been created from nothing!
Once you get some practice making graphs, you realize how easy it is to manipulate them to your advantage. The best protection against inaccurate figures may be firsthand practice in making them yourself.
(If you want a good book on making legitimate data visualizations, check out The Visual Display of Quantitative Information by Edward Tufte or Fundamentals of Data Visualization by Claus Wilke.)
4. Small Samples Produce Shocking Statistics
Would you be surprised if I told you the highest cancer rates tend to occur in the counties with the smallest populations? Not that shocking. How about when I add that the lowest cancer rates also tend to occur in counties with the lowest number of people? This a verified example of what occurs with small sample sizes: extreme values.
Any time researchers conduct a study, they use what is called a sample: a subset of the population meant to represent the entire population. This might work fine when the sample is large enough and has the same distribution of the larger population, but often, because of limited funding or response rates, psychological, behavioral, and medical studies are conducted with small samples, leading to results that are questionable and cannot be reproduced.
Scientists are usually limited to small samples by legitimate problems, but advertisers use small numbers of participants in their favor by conducting many tiny studies, one of which will produce a positive result. Humans are not great at adjusting for sample sizes when evaluating a study which in practice means we treat the results of a 1000 person trial the same as a 10 person trial. This is known as “insensitivity to sample size” or “sample size neglect”.
Here’s another example; if you consider yourself to be data literate, then you will have no problem with this question:
A certain town is served by two hospitals. In the larger hospital, about 45 babies are born each day, and in the smaller hospital, about 15 babies are born each day. As you know, about 50% of all babies are boys. However, the exact percentage varies from day to day. Sometimes it may be higher than 50%, sometimes lower.
For a period of 1 year, each hospital recorded the days on which more than 60% of the babies born were boys. Which hospital do you think recorded more such days?
1. The larger hospital
2. The smaller hospital
3. About the same (that is, within 5% of each other)
If you guessed 2., then congratulations, you are data literate! The reasoning is the smaller the sample size, the more extreme the values. (This is from Judgment under Uncertainty: Heuristics and Biases by Tversky and Kahnemann. I’d highly recommend reading this paper and Thinking, Fast and Slow, to learn about cognitive biases that affect our decision-making.)
You can test the principle that small samples produce extreme results by flipping a coin. With a small sample, say 5 tosses, there is a good chance you get 4 tails. Does this mean the coin always comes up 80% tails? No, this means your sample is too small to draw any significant conclusions.
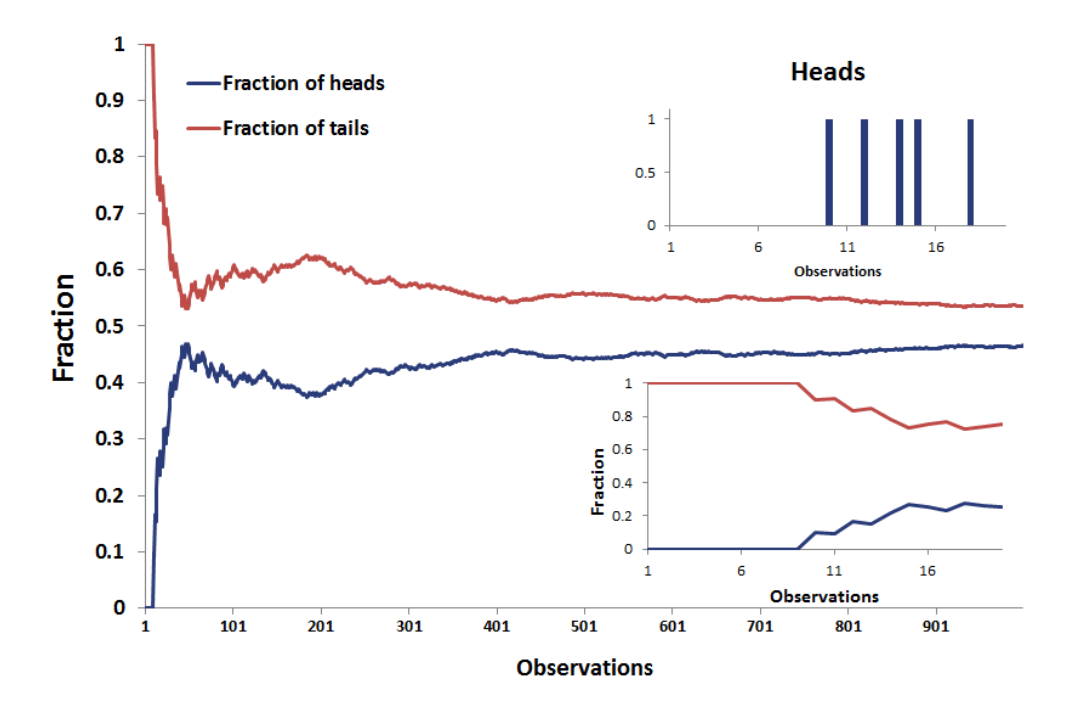 With smaller sample sizes, we get more extreme results (Source)
With smaller sample sizes, we get more extreme results (Source)
This trick is often used when marketing products by asking a small number of people about a particular brand. You can get impressive-sounding numbers (90% of doctors like this toothpaste) if you repeatedly survey small groups and only report the favorable results. Ask a small group, look at the results, throw away the bad, and repeat until you get the stats you need!
The solution to avoid being fooled by small sample sizes is to just look for the number of observations in the data. If not given, then assume whoever took the study has something to hide and the statistics are worthless. Behavioral scientists have shown that most of us are fallible to neglecting sample size; don’t make the same mistake — trust a large number of observations, not shocking statistics from small samples.
5. Look at all the Numbers that Describe a Dataset
Checking the sample size can be one way to avoid getting fooled by data, but only if the sample size is provided. Another trick used to mislead consumers of data is to avoid listing relevant numbers that describe a dataset, such as the count of observations, the spread of the data (range), the uncertainty about the data (standard error), the quantiles of the data, and so on. Each of these can be used to get a deeper dive into the data, which often goes against the interest of whoever presents the dataset.
For instance, if you hear that the average (more on this below) temperature in a city is 62 degrees F for the year, that is not helpful without knowing the maximum and minimum. The city could get as cold as -20 F and as warm as 120 F but still average out to a comfortable value. In this case, as in many others, a single number is not adequate to describe a dataset.
As another example from the book, if you have two children, one of whom tests a 99 on IQ and the other a 102, you really should not tell them to avoid comparisons. Why? Because IQ tests can have a standard error of around 3 points which means a child scoring a 99 once would be expected to score between 96 and 102 about 68% of the time. The overall difference might not be significant and could reverse itself in repeated testing. In other words, by leaving out the expected standard error in the results, you can draw a more drastic conclusion than that offered by the data.
Studies that don’t report more than one number usually have something to hide. Likewise, if a graph looks like it cuts off some of the data, it’s not trustworthy. It’s too easy to change a narrative by subsetting data.
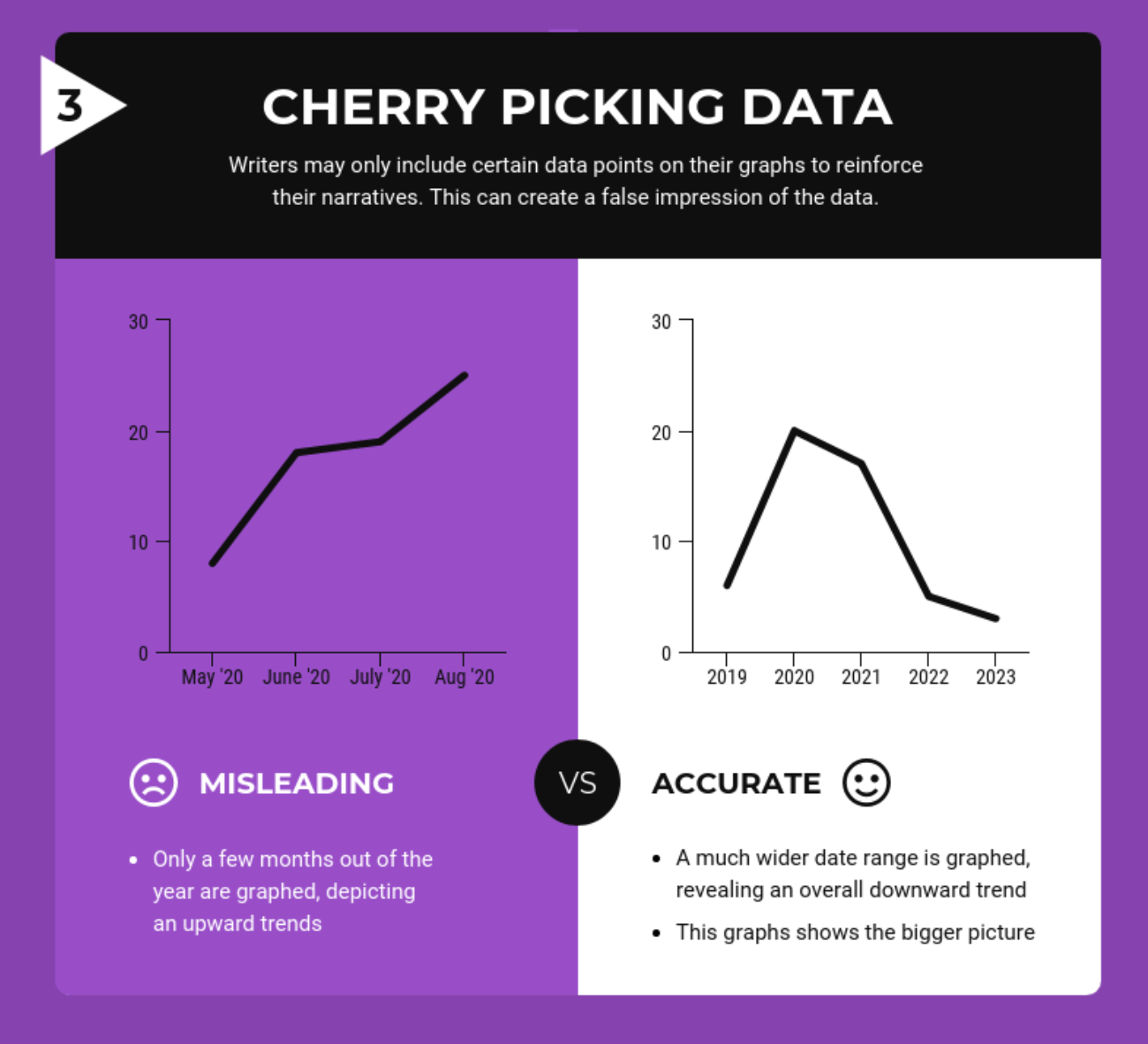 Graphs can change based on data shown (Source)
Graphs can change based on data shown (Source)
Think of it this way: if there was a medicine that increased lifespan by 2 years on average would you take it? Would it change your mind if the worst impact was a loss of 12 years of life and the maximum a gain of 14 years? It usually is the details that matter and one summary statistic cannot tell the whole story.
6. Check which Average is Used
Another useful way to tell whatever story you want with data is to vary the definition of “average”. You have 3 options (maybe more if you’re clever):
- Mean: sum the values and divide by the number of observations
- Median: order the values from smallest to greatest and find the middle
- Mode: find the value that occurs most often
I’ve written about this issue before (see here for details), and the basic idea is: the mean and median of a distribution are the same only if it is normal and we live in a world with mostly non-normal data. This means the mean and median of a dataset are not the same value, often by a considerable amount.
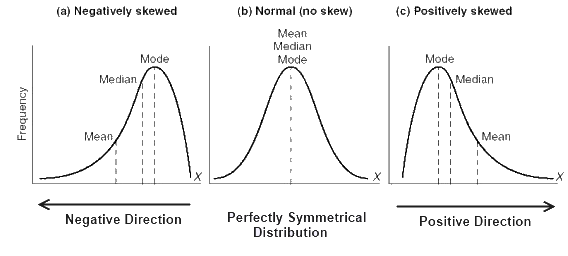 Mean vs Median vs Mode in Normal and Skewed Data (Source)
Mean vs Median vs Mode in Normal and Skewed Data (Source)
For example, the mean and median income in the United States differ by about $16,000. By choosing which value to report as the average, politicians, marketers, and CEOs can draw opposing conclusions from the same data.
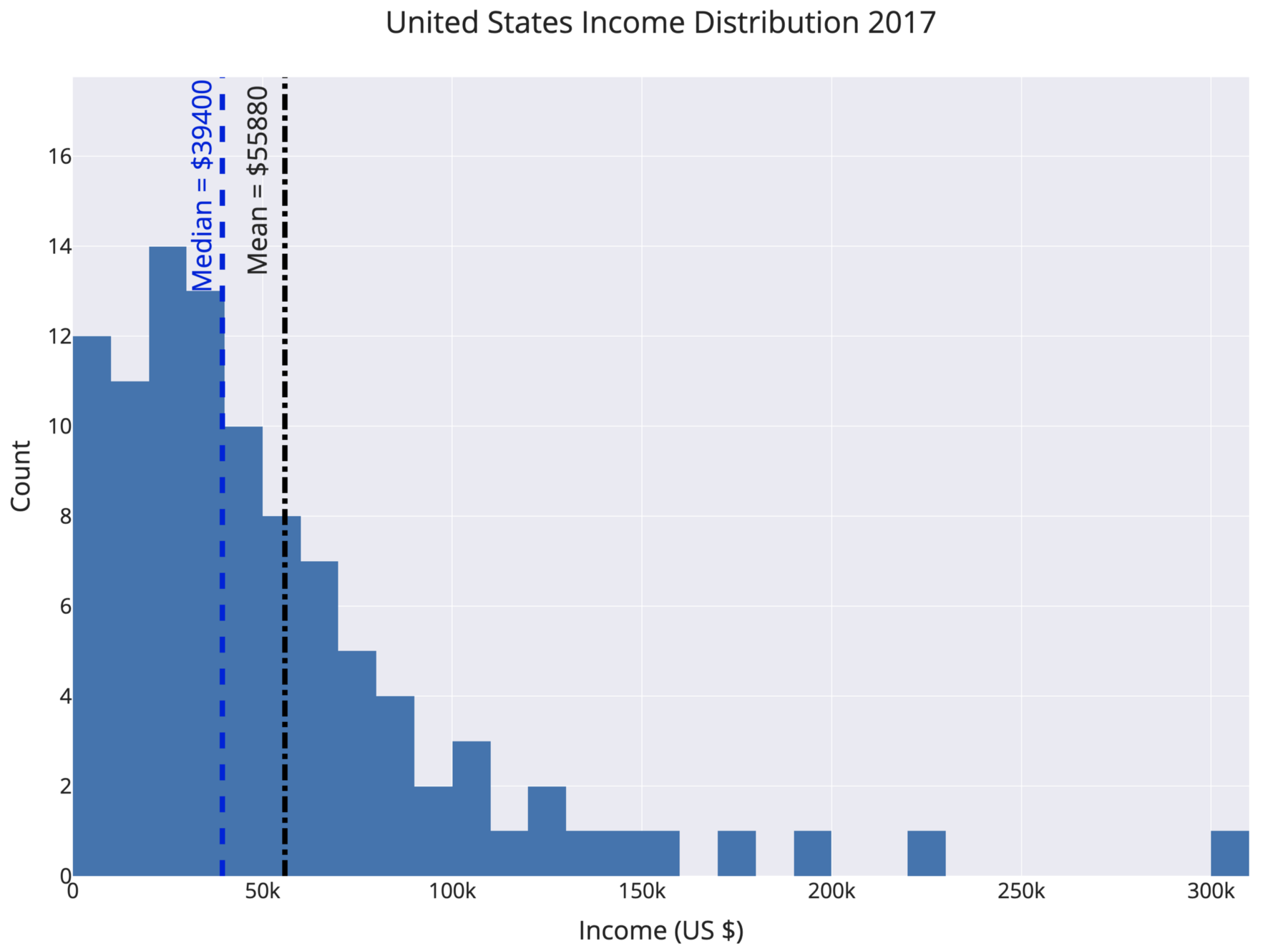 A skewed distribution with different mean and median (from my story on types of averages.)
A skewed distribution with different mean and median (from my story on types of averages.)
The way to avoid this is to look at the mean, median, and mode of a dataset (again you need all these numbers!). Figure out which one is most appropriate (usually the median for highly skewed datasets such as income, city size, life span, housing prices and so on) and use that if you need a one figure summary. If you can, graph the entire set of values in a histogram and look at the distribution. Try to use more than a single number to describe a dataset, and if you report an average, specify which you are using!
7. Use Comparisons to a Common Baseline
When viewing a statistic, the important question often is not what is the value, but how does the current value compare to the previous value? In other words, what is the relative change compared to the absolute magnitude. If I tell you the US GDP was $19.39 trillion in 2017, that sounds incredible because of your everyday experience. However, if you compare that to US GDP in the previous year, $18.62 trillion, it doesn’t look nearly as impressive.
Data is often on scales with which we are unfamiliar, and we need a comparison to other numbers to know if a statistic represents a real change. Is a mean radius of 3389 km for Mars large? I have no conception of what that means until it’s compared to other planets!
 Compare stats to other similar numbers (Source)
Compare stats to other similar numbers (Source)
Not only do we want to compare a statistic to values in the past and to numbers in the same category, but we also want to make sure the definition of the stat doesn’t change. According to “How to Lie”, The number of farms in the US increased from 1930 to 1935 by 500,000 because the definition of a farm from the Census Bureau changed! The easiest way to lower unemployment is just to change the definition to exclude people who have stopped looking for work.
Changes in the way data is gathered or in the definition of values can often produce extreme results mistaken for actual trends. To counter this, first, look at the entire series of values for perspective. Second, make sure the definition has not changed over the time range. Only then can you start to draw conclusions from the data series. You can scare people by saying New York had 289 murders in 2018, but when you compare that to 2245 in 1990, you realize New York City has never been safer! It’s usually the comparison that matters; don’t let an isolated number sway your rational thinking.
8. Look for Bias in Sample Selection
Remember when we talked about all data being gathered from samples which we hope are representative of the population? In addition to being concerned about sample size, we also need to look for any bias in the sample.
This could come from the measurement method used: a landline phone screen might favor wealthier, older participants. It could also come from the physical location: surveying only people who live in cities because it’s cheaper might bias results toward more progressive views. Sample bias is particularly prevalent in political polling where 2016 showed that sometimes samples are not representative of an entire population.
 Sampling Bias in Action (Source)
Sampling Bias in Action (Source)
When examining a study, we need to ask who is being included in the sample and who is being excluded. For decades, psychology and sociology studies have been hurt by the WEIRD bias. Samples only included people (often college students) from Western, Education, Industrialized, Rich, Democratic, Nations. It’s hard to reasonably say a survey represents all of humanity when the participants are this limited!
We should also look for sampling bias in our sources of information. Most of us now impose information selection bias on our selves by choosing sources that we tend to agree with. This leads to dangerous situations where we don’t encounter people who have different opinions and so we grow more entrenched in our views. The solution to this is simple but difficult: read different sources of news, particularly those that don’t agree with you.
If you are a New York Times reader, try the Wall Street Journal for a while. For those who are feeling adventurous, you can even try talking to people who disagree with you. While this may seem intimidating, I’ve found that people who disagree outwardly often have more in common — the same core driving desires — motivating them to choose their respective sides. It’s much easier to come to a common understanding in person but even engaging in civil discourse online is possible and productive and can help you escape a self-imposed information-selection bias.
In summary, we need to be wary both of outside sampling bias and self-created sampling bias from our choice of media sources. You would not like someone telling you to read only a single newspaper, so don’t do the same to yourself. Diverse viewpoints lead to better outcomes, and incorporating different sources of information with varying opinions will give you a better overall picture of events. We can’t always get to the complete truth of a matter, but we can at least see it from multiple sides. Similarly, when reading a study, make sure you recognize that the sample may not be indicative of the entire population and try to figure out which way the bias goes.
9. Be Wary of “Big Names” on Studies and Scrutinize Authority
Huff describes the idea of an “O.K name” as one added to a study to lend it an air of authority. Medical professionals (doctors), universities, scientific institutions, and large companies have names that lead us to automatically trust the results they produce. However, many times these “experts” did not actually produce the work but only were tangentially involved and the name has been added to sway us. Other times, such as when cigarette makers used doctors to sell their deadly products, the authorities are directly paid to lie.
One way to avoid being persuaded by an impressive name is to “make sure the name on the study stands behind the study and not beside it.” Don’t see an institutional name and immediately assume the study is infallible. I don’t think we should look at the author or university until we’ve analyzed the statistics to avoid any unconscious bias we impose on ourselves.
Even when the results come from a confirmed “expert” that does not mean you should accept them without question. The argument from authority is a fallacy that occurs when we assume someone with greater power is more likely to be correct. This is false because past success has no bearing on whether current results are correct. As Carl Sagan put it: “Authorities must prove their contentions like everybody else.” (from The Demon-Haunted World: Science as a Candle in the Dark).
 The Appeal to Authority logical fallacy (Source)
The Appeal to Authority logical fallacy (Source)
No one is above skepticism, as we’ve seen throughout the history of science (remember when Aristotle said there were 5 elements? or when the president of IBM said “I think there is a world market for maybe five computers”.) Many of the greatest findings have come from challenging authority and accepted wisdom. A statistic with a big name attached should get just as much scrutiny as any other. Statistics and data have no allegiance to a higher power.
10. Don’t Place Too Much Faith in any One Statistic
The overall theme of “How to Lie with Statistics” is: view any single statistic with skepticism. Any number represents a distillation of a set of data, which was taken on a sample of a population by mistake-prone humans, using imperfect tools, in constantly changing conditions at a single point in time. The data was analyzed by another human, who works for an institution, which may have outside funders with differing motivations. Finally, the statistic or graph was delivered to you by a publisher that has its own interests in getting you to believe one idea.
All this leads to two conclusions:
- If you put all your faith in one number, then you will be overfitting to the particular circumstances that produced the number.
- Statistics and data are never purely objective. A statistic is one interpretation of uncertain data designed to persuade.
We should not completely abandon statistics and data gathering. With the right design, studies can find critical trends — smoking is bad for you, chloroflourocarbons created a hole in the ozone layer, greater wealth leads to more happiness, and flouridated water vastly improves dental health— that then lead to better overall outcomes. Rather, we need to acknowledge data gathering and processing is an uncertain process with many factors influencing the final numbers we see.
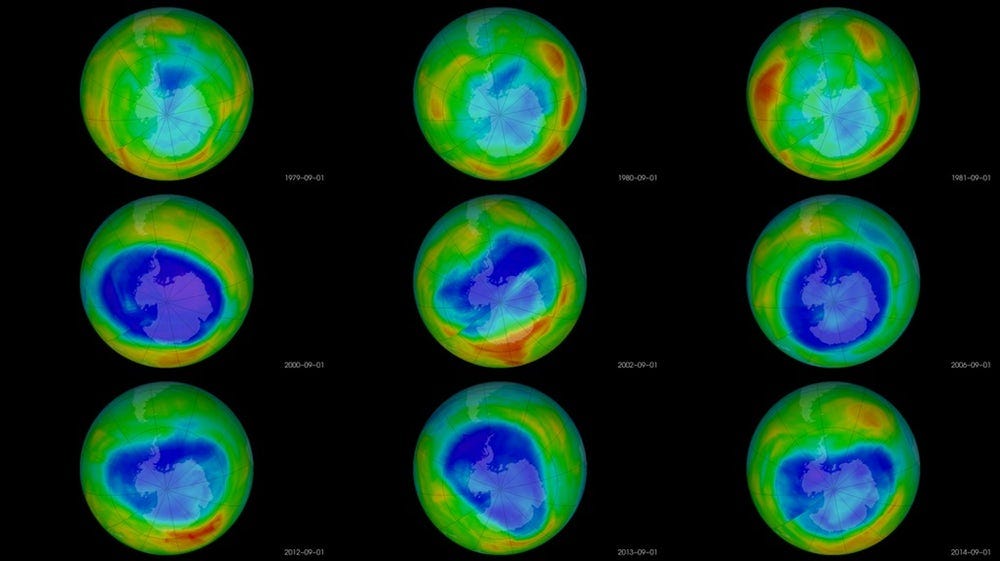 The identification and work to close the ozone layer hole is a data and environmental success story (Source)
The identification and work to close the ozone layer hole is a data and environmental success story (Source)
Humans are variable, and the world is variable — that’s part of what makes it so great to be living in it — and so we should be wary of statistics claiming to summarize it neatly in one graph or table. We should look for the range of values, report numbers with confidence intervals, gather more data before jumping to conclusions, compare multiple studies, and ask about the design of the data-gathering process.
We need to admit that we are wrong and change our minds when the burden of evidence is irrefutable. There may not be objective truths that hold for the entire universe, but we can become less wrong over time. That is basically the goal of science: light a little more of the darkness with each new study. This should also be the goal of data science: uncover a bit more of the structure of our world with each new dataset. At the same time, we need to recognize the limits of data and not over-generalize. More data is not a panacea, but more data with debate, multiple analyses, and scrutiny can lead to better real-world decisions and that’s what we hope for as data literate citizens.
Conclusions
If I’ve learned anything in the data science field, it’s that the most effective way to spend my time is to make a bar chart with 4 numbers. Machine learning modeling is cutting-edge, but in the end, all the CEO wants to see is a simple chart from which she can draw a conclusion. There is nothing inherently wrong with this: as data scientists, our job is to extract meaning from large quantities of data. Meaning does not imply showing hundreds of numbers, it means displaying a limited few with high value. How we present those numbers can make a large impact on how — or if — they are used.
 Simple charts are usually the most effective (Source)
Simple charts are usually the most effective (Source)
Data literacy means having the skills to interpret graphs, charts, and statistics and draw actionable conclusions. These conclusions do not have to agree with whoever produced the chart, and you should be skeptical when they do. As consumers of data products, we need to understand how easy it is to manipulate data to prove a point or turn a negative into a positive. Getting practice reading statistics and visualizations — actually reading a figure — helps. Another useful tactic is to make a lot of charts yourself. Practice using the best techniques and make sure to not deliberately mislead others.
The world is not a bad place, but there are people who don’t have your best wishes at heart. Often, they’ll use data as a tool to convince you to act in their interest and against your own. The best shield against these tactics is basic data literacy: understand how data can be manipulated and the ways you can break through the misconceptions. A healthy dose of skepticism is good for you personally and for the entire field of data science. With these lessons in mind, get out there and be a responsible producer and consumer of data.
As always, I welcome feedback and constructive criticism. I can be reached on Twitter @koehrsen_will.