Published on August 11, 2018
Writing creates opportunities, gives you critical communication practice, and makes you a better data scientist through feedback
It can be tempting to call a data science project complete after you’ve uploaded the final code to GitHub or handed in your assignment. However, if you stop there, you’re missing out on the most crucial step of the process: writing and sharing an article about your project. Writing a blog post isn’t typically considered part of the data science pipeline, but to get the most from your work, then it should be the standard last step in any of your projects.
There are three benefits to writing even a simple blog post about your work:
- Communication Practice: good code by itself it not enough. The best analysis will have no impact if you can’t make people care about the work.
- Writing Creates Opportunities: by exposing your work to the world, you’ll be able to form connections that can lead to job offers, collaborations, and new project ideas.
- Feedback: the cycle of getting better is: do work, share, listen to constructive criticism, improve work, repeat
Writing is one of those activities — exercise and education also come to mind — that might have no payout in the short term but almost unlimited potential rewards in the long term. Personally, I make $0 from the 10,000 daily views my blog posts receive, each of which takes 3–15 hours to write. Yet, I also wouldn’t have a full-time data science job were it not for my articles.
Moreover, I know the quality of my data science work is much higher, both because I intend to write about it, and because I used the previous feedback I’ve received, making the long term return from writing decidedly positive.


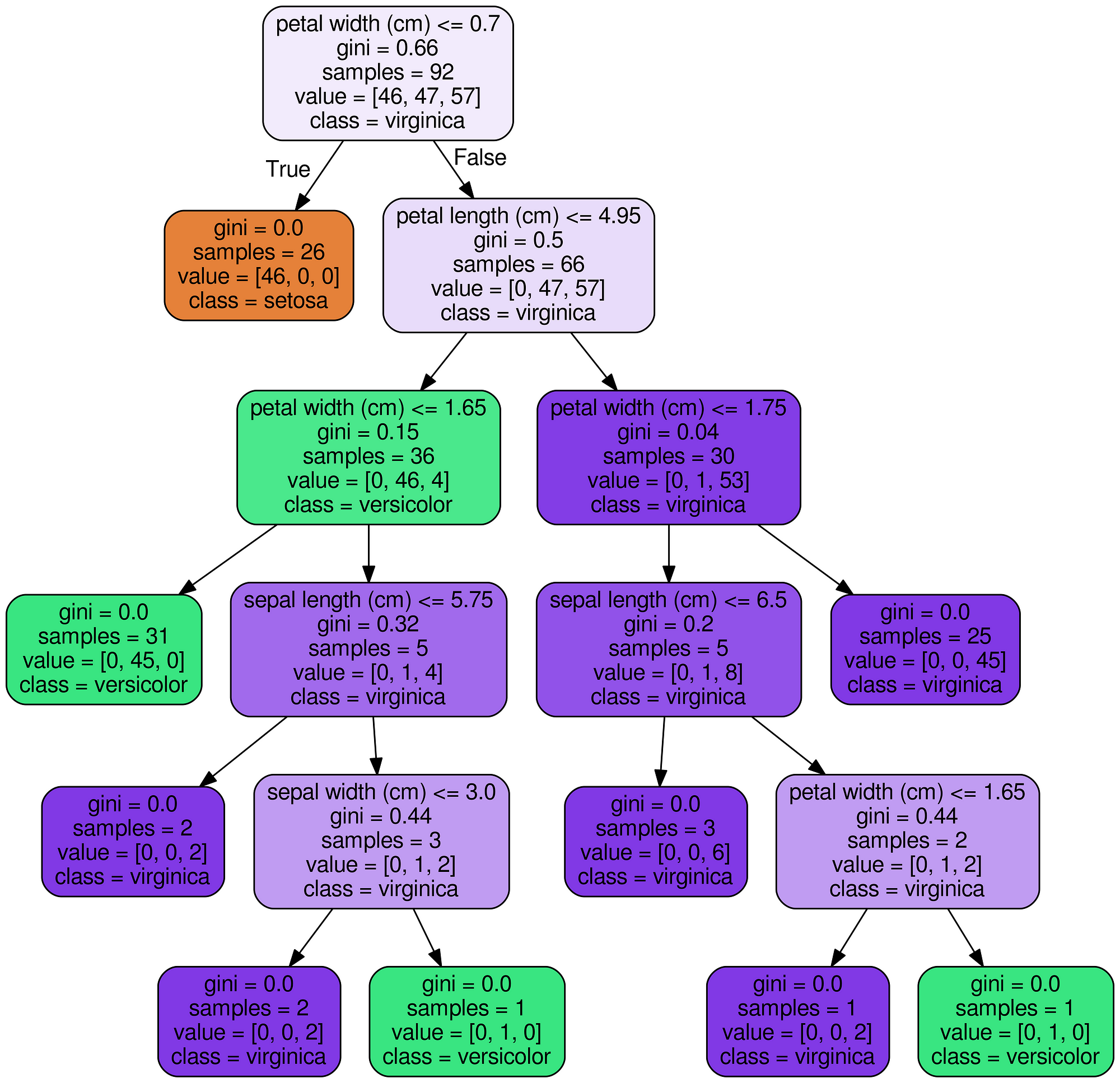 Decision Tree for Iris Dataset
Decision Tree for Iris Dataset


 Data Science is for more than just getting people to click on ads
Data Science is for more than just getting people to click on ads