
How To Generate Prediction Intervals With Scikit Learn And Python

Using the Gradient Boosting Regressor to show uncertainty in machine learning estimates
“All models are wrong but some are useful” — George Box. It’s critical to keep this sage advice in mind when we present machine learning predictions. With all machine learning pipelines, there are limitations: features which affect the target that are not in the data (latent variables), or assumptions made by the model which don’t align with reality. These are overlooked when we show a single exact number for a prediction — the house will be $450,300.01 —which gives the impression we are entirely confident our model is a source of truth.
A more honest way to show predictions from a model is as a range of estimates: there might be a most likely value, but there is also a wide interval where the real value could be. This isn’t a topic typically addressed in data science courses, but it’s crucial that we show uncertainty in predictions and don’t oversell the capabilities of machine learning. While people crave certainty, I think it’s better to show a wide prediction interval that does contain the true value than an exact estimate which is far from reality.
In this article, we’ll walk through one method of producing uncertainty intervals in Scikit-Learn. The full code is available on GitHub with an interactive version of the Jupyter Notebook on nbviewer. We’ll focus primarily on implementation, with a brief section and resources for understanding the theory at the end. Generating prediction intervals is another tool in the data science toolbox, one critical for earning the trust of non-data-scientists.
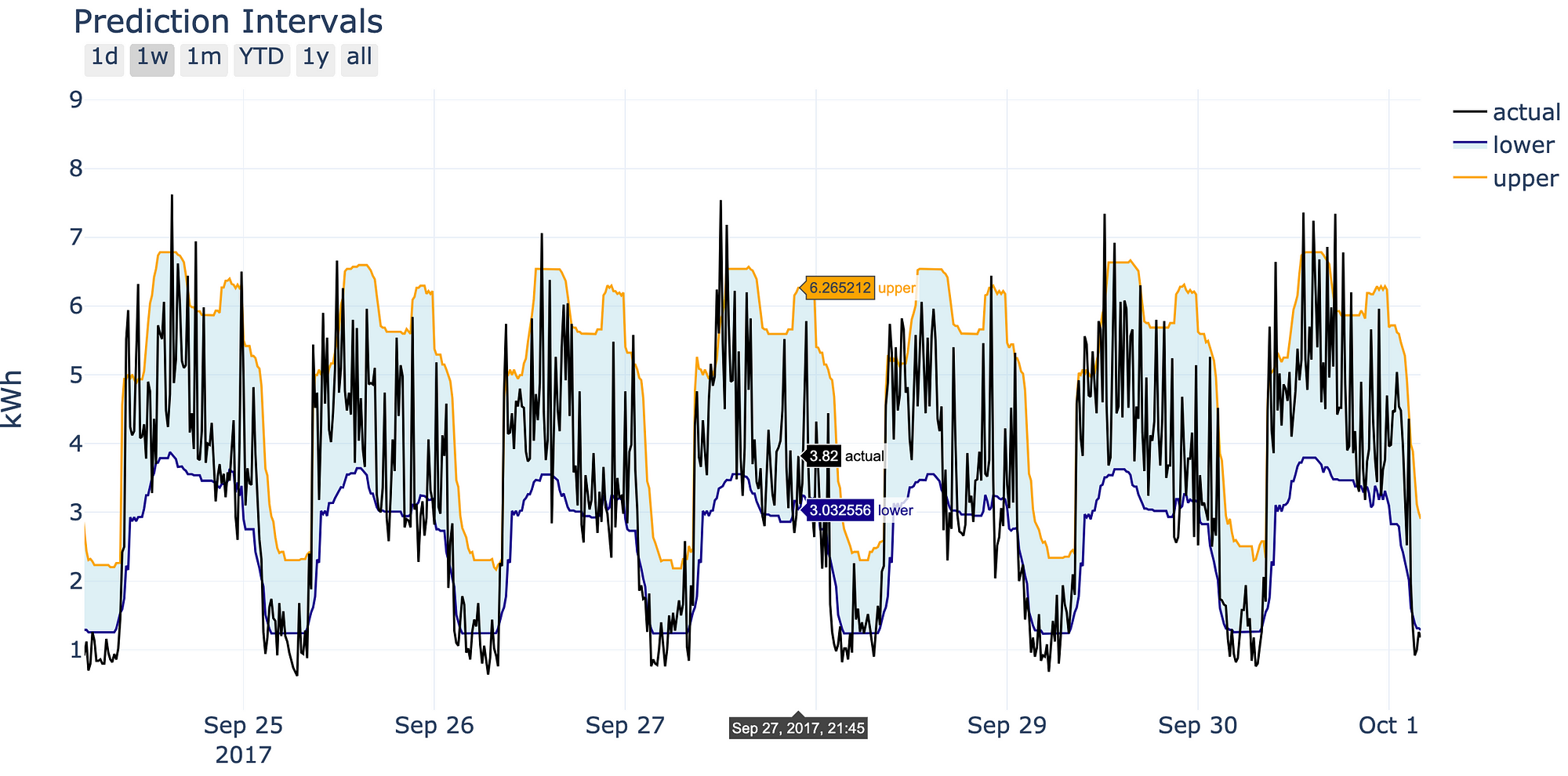 Prediction intervals we’ll make in this walkthough.
Prediction intervals we’ll make in this walkthough.



 Don’t let notebooks like this get onto GitHub.
Don’t let notebooks like this get onto GitHub.