
NYSERDA Tenant Energy Data Challenge
Presented in this article are my answers to the NYSERDA Tenant Energy Data Challenge.
The GitHub Repo contains the code used in this project.
Problem Statements
1 What is your forecasted consumption across all 18 tenant usage meters for the 24 hours of 8/31/20 in 15 minute intervals (1728 predictions)?
The forecasted consumption is submitted as a csv to the challenge submission form.
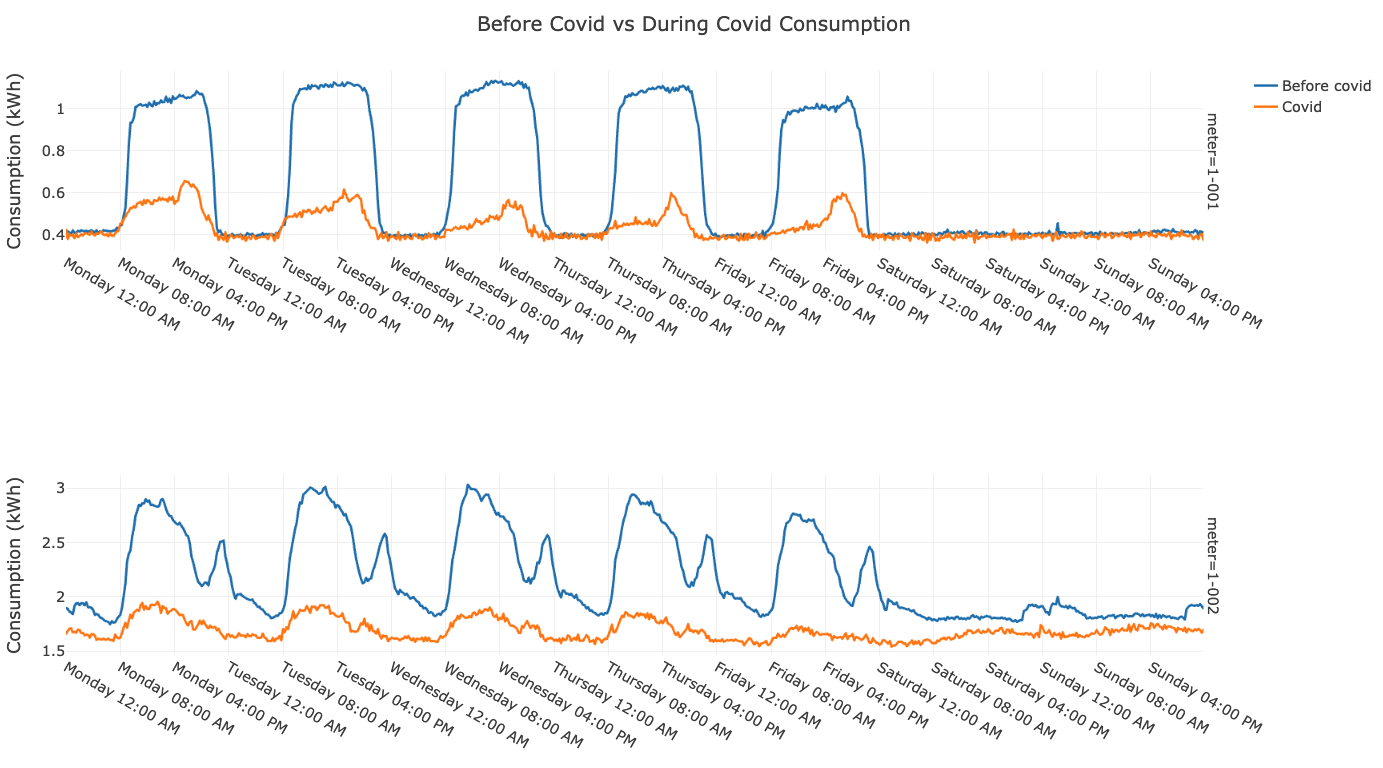
2 How correlated are building-wide occupancy and tenant consumption?
For every 10% decrease in occupancy, the consumption is expected to decrease by 3.1%.
- While some tenant meters surprisingly show an increase in consumption with a reduction in occupancy, the majority display the expected decrease in consumption.
- We can quantify this observation by stating the percentage decrease in consumption for every percentage decrease in occupancy, which, averaged over all the tenant meters, is 0.31.
- For every 10% decrease in occupancy, the consumption is expected to decrease by 3.1%.
The below stats show the expected change in consumption (positive values indicate a decrease in consumption) for every 10% decrease in occupancy.
| Tenant Meter | Consumption Decrease for 10% Occupancy Decrease (%) |
|---|---|
| Average | 3.10 |
| 1-001 | 4.15 |
| 1-002 | 2.77 |
| 1-003 | 2.97 |
| 1-004 | 3.55 |
| 1-005 | 1.61 |
| 1-006 | 4.47 |
| 1-007 | 3.31 |
| 1-008 | 2.47 |
| 1-009 | 1.27 |
| 1-010 | 3.15 |
| 1-011 | 6.66 |
| 1-012 | -0.66 |
| 1-013 | -0.99 |
| 1-014 | 2.43 |
| 1-015 | 3.88 |
| 1-016 | 5.89 |
| 1-017 | 0.13 |
| 1-018 | 5.87 |
| Building | 3.05 |
On a technical note, the average Pearson’s correlation coefficient (a standard method of measuring correlations) between the building-wide reduction in occupancy and tenant consumption is 0.60, a strongly positive correlation (as the reduction in occupancy increases, the reduction in consumption increases). As an interesting note, this value is negative for some meters, which display an increase in consumption with decreases in occupancy.



 404 pages from GitHub (left) and HopperMagic (right)
404 pages from GitHub (left) and HopperMagic (right)  Wayback Machine in operation on a
Wayback Machine in operation on a 


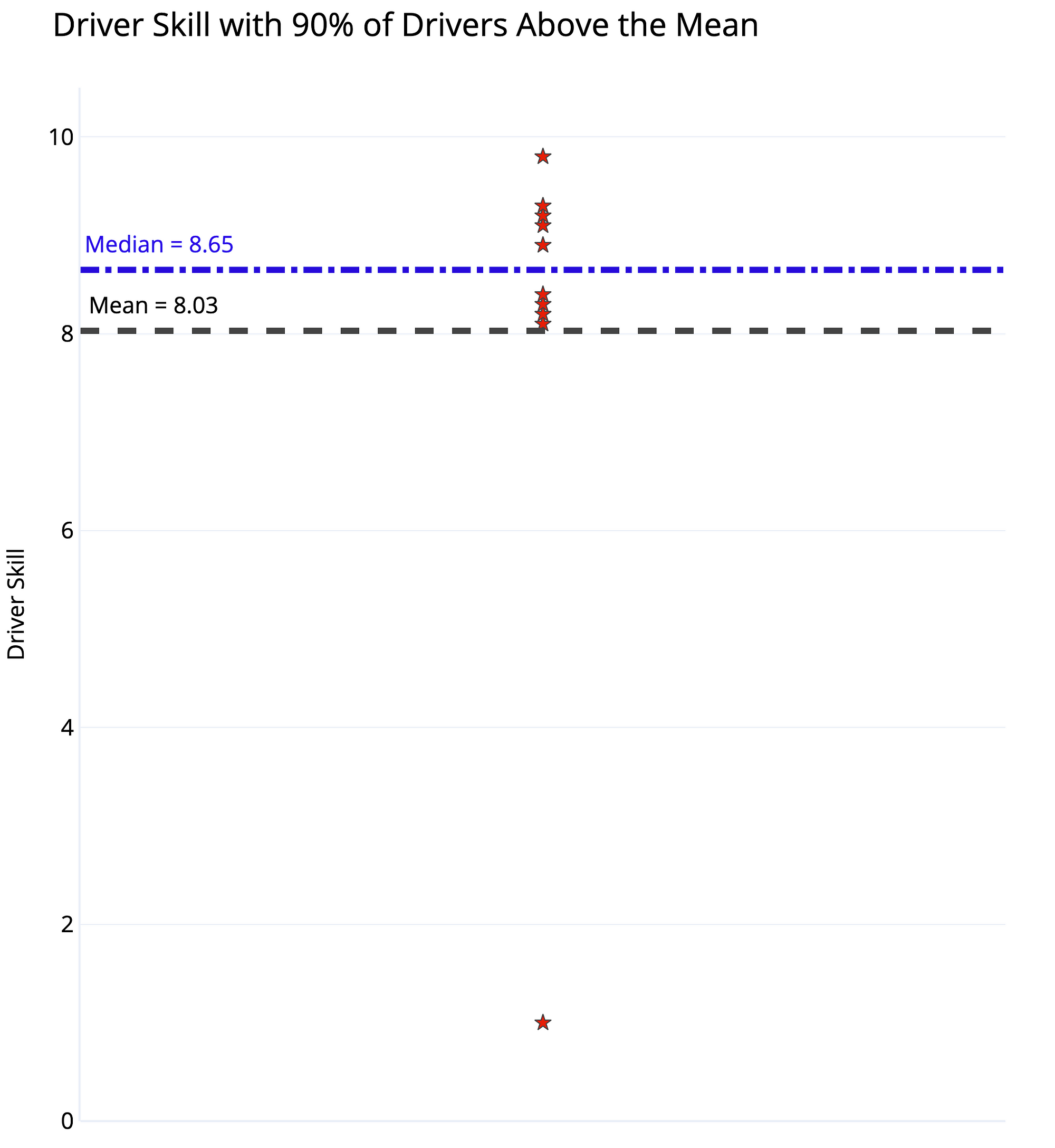 Driver Skill Dataset and Dot Plot with Mean and Median
Driver Skill Dataset and Dot Plot with Mean and Median