
A Review Of The Coursera Machine Learning Specialization
With so many high-quality options for studying machine learning, Coursera does not make the cut.**
Although I consider myself an ardent supporter of the democratization of education through online courses, I keep a healthy skeptical attitude towards what these classes can and cannot do. The Coursera Machine Learning Specialization from the University of Washington aims to help students “Build Intelligent Applications. Master machine learning fundamentals.” On these two self-declared criteria, the course fails. Ultimately, the specialization serves at most as a high-level overview of basic machine learning topics, but upon graduation, students will be hard-pressed to apply any of the concepts to real problems on their own. It’s difficult to assign a rating because the course might be better-suited for some individuals than others, but, comparing it to both the Udacity Machine Learning Nanodegree and college courses, I would give it 2 out of 5. The shallow assignments and lack of an involved project means the course does not provide students with transferable skills.
When I signed up for the specialization, it was with the promise of 4 separate courses and a hands-on capstone project. The four courses were each expected to take about 6 weeks to complete with 5–8 hours of work per week and consisted of the following: fundamentals, regression, classification, and clustering/retrieval. Unbeknownst to me, the capstone was removed from the specialization, a fact difficult to figure out as numerous official Coursera emails and videos still referred to an application we would build ourselves. Had there been a capstone, my opinion might have changed, but I cannot recommend a class with no significant project requiring implementing course concepts.

 No obvious conclusion from this perspective (
No obvious conclusion from this perspective (
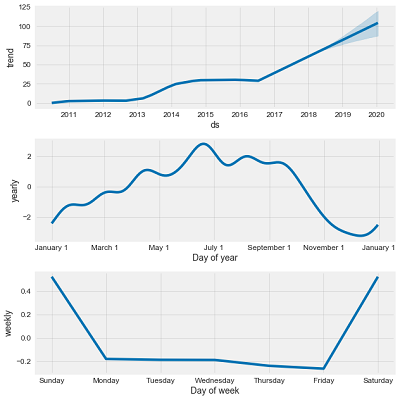 Example of Additive Model Decomposition
Example of Additive Model Decomposition
 One Tree in a Random Forest
One Tree in a Random Forest