Exploratory Data Analysis With R No Code
Examining the Doctor’s Appointment No-Show Dataset
Author’s Note: The following exploratory data analysis project was completed as part of the Udacity Data Analyst Nanodegree that I finished in May 2017. All code for this project can be found on my GitHub repository for the class. I highly recommend the course to anyone interested in data analysis (that is anyone who wants to make sense of the mass amounts of data generated in our modern world) as well as to those who want to learn basic programming skills in an applied setting. This version of the Exploratory Data Analysis project has all the code removed for readability. The version with all the R code included is also on Medium.
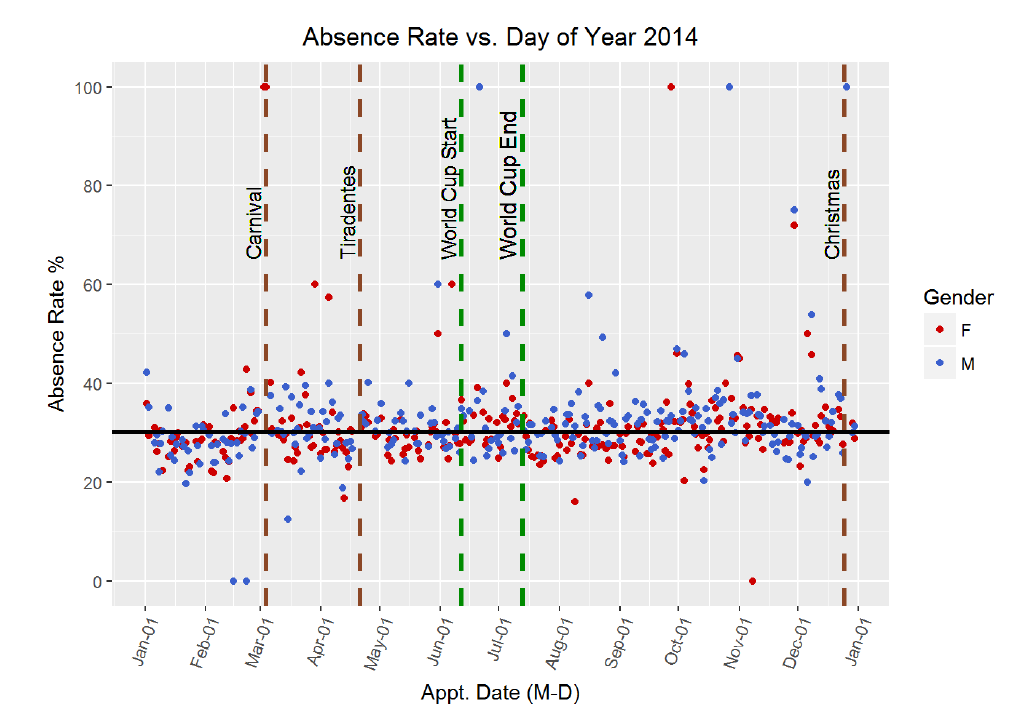
Doctor’s appointment no-shows are a serious issue in the public health care field. Missed appointments are associated with poorer patient outcomes and cost the health care system in the US nearly $200 each. Therefore, it comes as no small surprise that reducing the rate of no-shows has become a priority in the United States and around the world. Numerous studies have been undertaken in order to determine the most effective means of reducing rates of absenteeism at with varying degrees of success. The first step to solving the problem of missed appointments is identifying why a patient skips a scheduled visit in the first place. What trends are there among patients with higher absence rates? Are there demographic indicators or perhaps time-variant relationships hiding in the data? Ultimately, it was these questions that drove my exploratory data analysis. I was curious as to the reasons behind missed appointments, and wanted to examine the data to identify any trends present. I choose this problem because I believe it is an excellent example of how data science and analysis can reveal relationships which can be implemented in the real-world to the benefit of society.
I wanted to choose a dataset that was both relatable and could be used to make smarter decisions. Therefore, I decided to work with medical appointment no shows data available on Kaggle. This dataset is drawn from 300,000 primary physician visits in Brazil across 2014 and 2015. The information about the appointment was automatically coded when the patient scheduled the appointment and then the patient was marked as having either attended or not. The information about the appointment included demographic data, time data, and conditions concerning the reason for the visit.
 Labeled Faces in the Wild Dataset
Labeled Faces in the Wild Dataset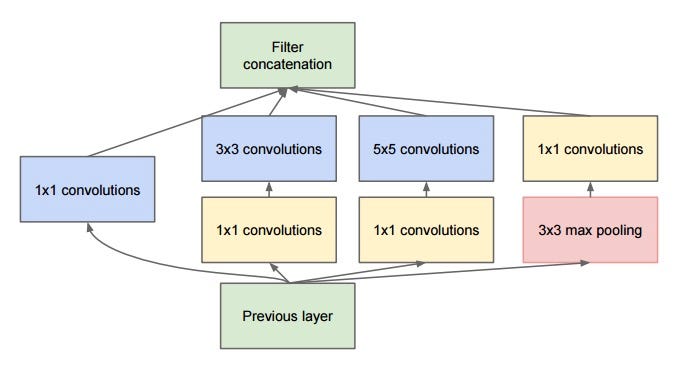 Inception Module: The Building Block of the Inception CNN
Inception Module: The Building Block of the Inception CNN