
Machine Learning With Python On The Enron Dataset
##Investigating Fraud using Scikit-learn
Author’s Note: The following machine learning project was completed as part of the Udacity Data Analyst Nanodegree that I finished in May 2017. All of the code can be found on my GitHub repository for the class. I highly recommend the course to anyone interested in data analysis (that is anyone who wants to make sense of the mass amounts of data generated in our modern world) as well as to those who want to learn basic programming skills in an project-focused format.
Introduction
Dataset Background
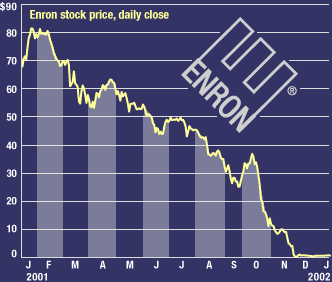
The Enron email + financial dataset is a trove of information regarding the Enron Corporation, an energy, commodities, and services company that infamously went bankrupt in December 2001 as a result of fraudulent business practices. In the aftermath of the company’s collapse, the Federal Energy Regulatory Commission released more 1.6 million emails sent and received by Enron executives in the years from 2000–2002 (History of Enron). After numerous complaints regarding the sensitive nature of the emails, the FERC redacted a large portion of the emails, but about 0.5 million remain available to the public. The email + financial data contains the emails themselves, metadata about the emails such as number received by and sent from each individual, and financial information including salary and stock options. The Enron dataset has become a valuable training and testing ground for machine learning practicioners to try and develop models that can identify the persons of interests (POIs) from the features within the data. The persons of interest are the individuals who were eventually tried for fraud or criminal activity in the Enron investigation and include several top level executives. The objective of this project was to create a machine learning model that could separate out the POIs. I choose not to use the text contained within the emails as input for my classifier, but rather the metadata about the emails and the financial information. The ultimate objective of investigating the Enron dataset is to be able to predict cases of fraud or unsafe business practices far in advance, so those responsible can be punished, and those who are innocent are not harmed. Machine learning holds the promise of a world with no more Enrons, so let’s get started!
 Display the Sensors Tab
Display the Sensors Tab
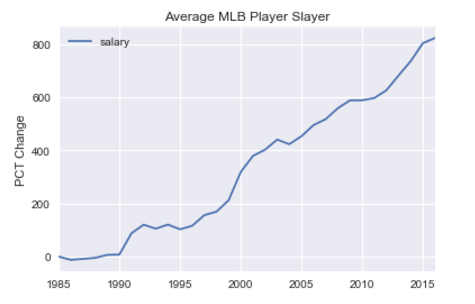 Percentage Change of Average MLB Player Salary 1985–2015
Percentage Change of Average MLB Player Salary 1985–2015