
My Weaknesses as a Data Scientist
Without recognizing our weak points, we’ll never be able to overcome them
If modern job interviews have taught us anything, it’s that the correct answer to the question “What’s your biggest weakness?” is “I work too hard.” Clearly, it’d be ludicrous to actually talk about our weaknesses, right? Why would we want to mention what we can’t yet do? While job applications and LinkedIn profile pages don’t encourage us to disclose our weak points, if we never admit our deficiencies, then we can’t take the steps to address them.
The path to getting better in an endeavor is simple:
- Determine where you are now: identify weaknesses
- Figure out where you want to be: make a plan to get there
- Execute on the plan: take one small action at a time
We rarely get past the first step: especially in technical fields, we keep our heads down and continue working, using the skills we already have rather than attaining new ones that would make our jobs easier or open us up to new opportunities. Self-reflection — evaluating ourselves objectively — may seem like a foreign concept, but being able to take a step back and figuring out what we could do better or more efficiently is critical to advancing in any field.
With that in mind, I’ve tried to take an objective look at where I am now and identified 3 areas to work on to make me a better data scientist:
- Software engineering
- Scaling data science
- Deep learning
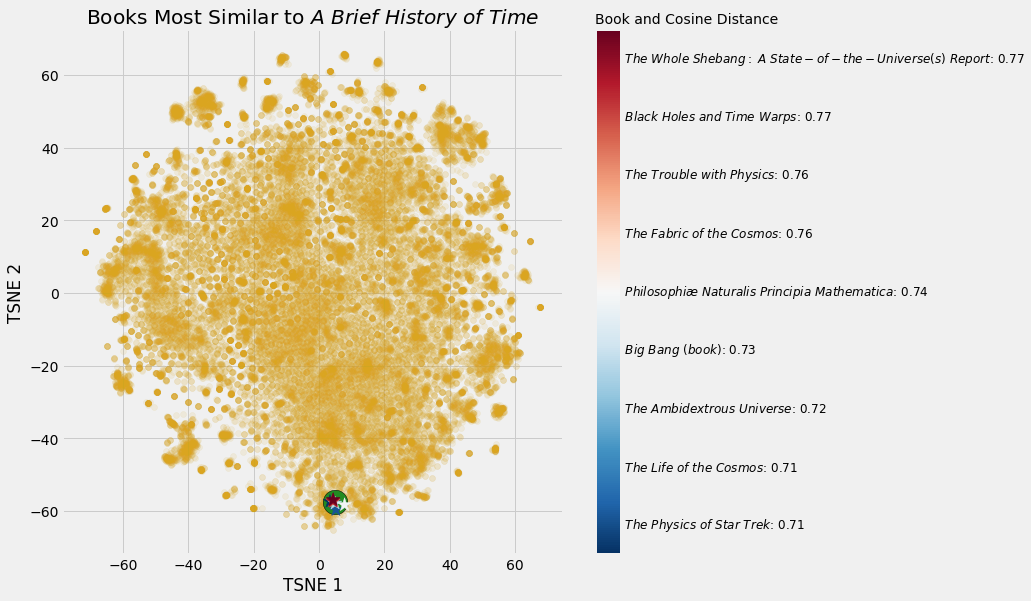 Most Similar Books to Stephen Hawking’s A Brief History of Time
Most Similar Books to Stephen Hawking’s A Brief History of Time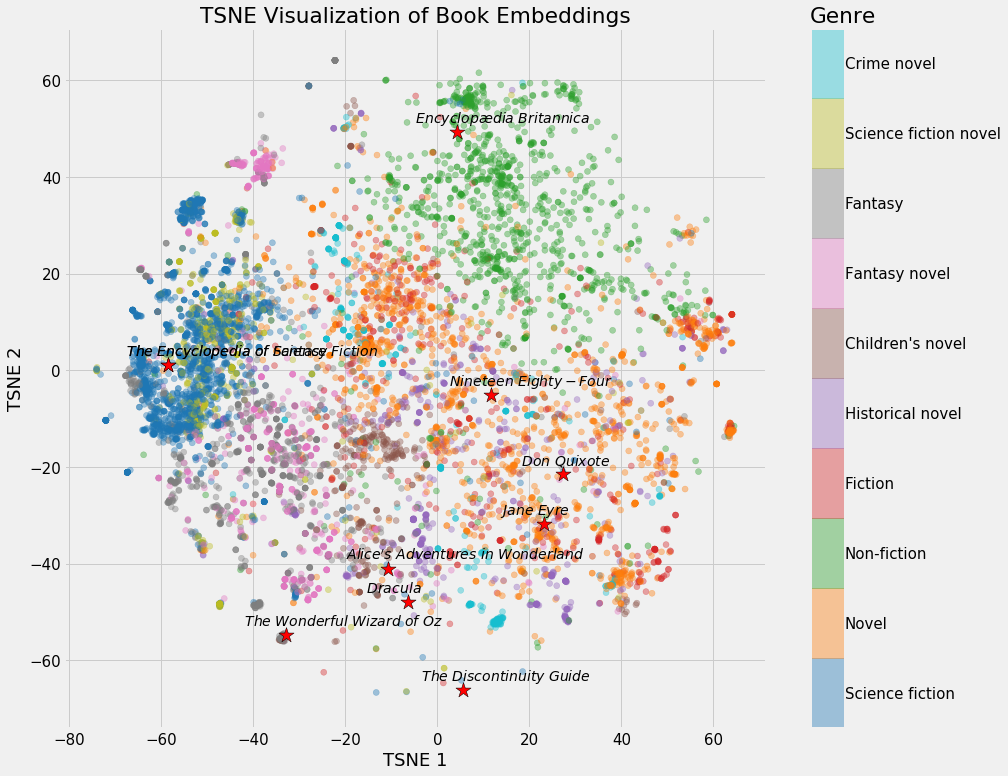 Neural Network Embedding of all books on Wikipedia. (
Neural Network Embedding of all books on Wikipedia. (