
Statistical Significance Explained

What does it mean to prove something with data?
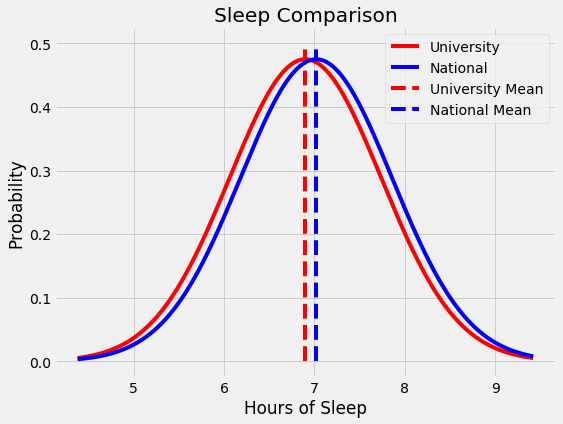
As the dean at a major university, you receive a concerning report showing your students get an average of 6.80 hours of sleep per night compared to the national college average of 7.02 hours. The student body president is worried about the health of students and points to this study as proof that homework must be reduced. The university president on the other hand dismisses the study as nonsense: “Back in my day we got four hours of sleep a night and considered ourselves lucky.” You have to decide if this is a serious issue. Fortunately, you’re well-versed in statistics and finally see a chance to put your education to use!
 How can we decide if this is meaningful?
How can we decide if this is meaningful?
Statistical significance is one of those terms we often hear without really understanding. When someone claims data proves their point, we nod and accept it, assuming statisticians have done complex operations that yielded a result which cannot be questioned. In fact, statistical significance is not a complicated phenomenon requiring years of study to master, but a straightforward idea that everyone can — and should — understand. Like with most technical concepts, statistical significance is built on a few simple ideas: hypothesis testing, the normal distribution, and p values. In this article, we will briefly touch on all of these concepts (with further resources provided) as we work up to solving the conundrum presented above.

 The difference between data (left) and knowledge (right)
The difference between data (left) and knowledge (right)
 Out of simple ideas come powerful systems (
Out of simple ideas come powerful systems (
 Sometimes even grad students should go outside
Sometimes even grad students should go outside Well said
Well said